From 42f512133535ddd3b542abecc5c96f8a0da6764b Mon Sep 17 00:00:00 2001
From: Adrian Kummerlaender
Date: Tue, 17 Jan 2017 20:44:31 +0100
Subject: Update markdown syntax to use pandoc's peculiarities
---
.../2010-02-06_debian_auf_dem_sheevaplug.md | 30 ++++----
.../2010-02-24_traffic_ueberwachung_mit_vnstat.md | 2 +-
...r_und_automatische_uebersetzung_mit_dem_n900.md | 6 +-
.../articles/2011-03-31_sheevaplug_ueberwachung.md | 24 +++----
...1-06-14_darstellen_von_gps_daten_mit_gnuplot.md | 32 ++++-----
.../2011-09-03_die_sache_mit_dem_netzteil.md | 2 +-
...1-10-01_lighttpd_konfiguration_fuer_symphony.md | 20 +++---
.../2011-10-02_tarsnap_backups_fuer_paranoide.md | 14 ++--
...-16_kurztipp_n900_retten_ohne_neu_zu_flashen.md | 5 +-
.../2011-11-08_informationen_umformen_mit_xsl.md | 15 ++--
.../2012-01-25_erfahrungen_mit_openslides.md | 9 ++-
...2-04-07_mobile_endgeraete_und_freie_software.md | 2 +-
...-08-29_erfahrungen_mit_einer_ssd_unter_linux.md | 5 +-
...rung_mit_kvm_und_virtuelle_netzwerke_mit_vde.md | 72 +++++++++----------
...functions_local_to_a_translation_unit_in_cpp.md | 10 ++-
.../2013-10-06_notizen_zu_cpp_und_unicode.md | 26 ++++---
...res_as_tuples_using_template_metaprogramming.md | 35 ++++-----
...013-12-21_musikalischer_jahresruekblick_2013.md | 4 +-
...tiated_class_template_specializations_in_cpp.md | 15 ++--
...4-07-11_mapping_arrays_using_tuples_in_cpp11.md | 14 ++--
...014-10-30_expanding_xslt_using_xalan_and_cpp.md | 15 ++--
...14_a_look_at_compile_time_computation_in_cpp.md | 20 +++---
...e_as_a_metaphor_for_template_metaprogramming.md | 47 +++++-------
...2015-09-18_nokia_heir_and_hardware_keyboards.md | 2 +-
.../articles/2015-09-24_the_joys_of_ipv6.md | 66 +++++++++--------
...02-21_notes_on_function_interposition_in_cpp.md | 48 ++++++-------
...lisierung_von_metriken_in_voronoi_diagrammen.md | 84 +++++++++++-----------
source/00_content/pages/about.md | 2 +-
source/00_content/pages/impressum.md | 1 -
source/00_content/pages/projects/binary_mapping.md | 5 +-
source/00_content/pages/projects/build_xslt.md | 10 ++-
.../pages/projects/codepoint_iterator.md | 5 +-
source/00_content/pages/projects/const_list.md | 5 +-
source/00_content/pages/projects/input_xslt.md | 13 ++--
source/00_content/pages/projects/kv.md | 21 +++---
source/00_content/pages/projects/static_xslt.md | 4 +-
source/00_content/pages/projects/telebot.md | 10 ++-
source/00_content/pages/projects/trie.md | 5 +-
source/00_content/pages/projects/type_as_value.md | 5 +-
39 files changed, 328 insertions(+), 382 deletions(-)
(limited to 'source')
diff --git a/source/00_content/articles/2010-02-06_debian_auf_dem_sheevaplug.md b/source/00_content/articles/2010-02-06_debian_auf_dem_sheevaplug.md
index c7bc555..fb82abb 100644
--- a/source/00_content/articles/2010-02-06_debian_auf_dem_sheevaplug.md
+++ b/source/00_content/articles/2010-02-06_debian_auf_dem_sheevaplug.md
@@ -4,54 +4,48 @@ Auf dem herkömmlichen [Weg](http://www.cyrius.com/debian/kirkwood/sheevaplug/)
Als erstes laden wir uns den normalen SheevaInstaller herunter mit dem man Ubuntu 9.04 auf dem Sheeva installieren kann ([klick](http://www.plugcomputer.org/index.php/us/resources/downloads?func=select&id=5)). Nach dem wir den Tarball heruntergeladen haben sollte man ihn entpacken. Als nächstes laden wir ein Debian Lenny / Squeeze Prebuild von [hier](http://www.mediafire.com/sheeva-with-debian) herunter. Nun ersetzen wir die „rootfs.tar.gz“ mit der neuen Debian „rootfs.tar.gz“. Bevor wir jedoch mit der Installation beginnen müssen wir die neue „rootfs.tar.gz“ mit „tar“ entpacken. Dazu führen wir auf der Konsole
-~~~
+```sh
mkdir rootfs
cd rootfs
tar xfvz rootfs.tar.gz
-~~~
-{: .language-sh}
+```
aus. In dem Ordner führen wir nun ein
-~~~
+```sh
mknod -m 660 dev/ttyS0 c 4 64
-~~~
-{: .language-sh}
+```
aus. Mit diesem Befehl wird die fehlende serielle Konsole erstellt. Jetzt verpacken wir das Archiv wieder mit
-~~~
+```sh
tar cfvz ../rootfs.tar.gz *
-~~~
-{: .language-sh}
+```
Den gesamten Inhalt des Ordners /install im SheevaInstaller-Verzeichniss müssen wir jetzt auf einen mit FAT formatierten USB-Stick kopieren. Diesen stecken wir schon einmal in den USB-Port des Sheevas. Als nächstes verbinden wir den SheevaPlug mit einem Mini-USB Kabel mit unserem Computer und führen das Script „runme.php“ aus. Wenn alles klappt wird nun ein neuer Boot-Loader und das rootfs auf den Plug kopiert. Dannach ist unser Debian einsatzbereit.
Sollte der Plug den USB-Stick nicht erkennen und somit auch das rootfs nicht kopieren können hilft es einen anderen USB-Stick zu verwenden. Beispielsweise wurde mein SanDisk U3 Stick trotz gelöschtem U3 nicht erkannt. Mit einem anderen Stick funktionierte es jedoch tadelos. Auch sollte der Stick partitioniert sein. Der Bootloader des SheevaPlugs kann nicht gut mit direkt auf dem Stick enthalten Dateisystemen umgehen. Wenn die MiniUSB Verbindung beim Ausführen des runme-Scripts nicht funktionieren sollte hilft oft ein
-~~~
+```sh
rmmod ftdi_sio
-~~~
-{: .language-sh}
+```
und
-~~~
+```sh
modprobe ftdi_sio vendor=0x9e88 product=0x9e8f
-~~~
-{: .language-sh}
+```
(beides als root). Ebenfalls sollte kein zweites Serielles-Gerät am Computer angeschlossen sein.
Bei neueren Plugs kann man bei Problemen bei der Installation die Datei „uboot/openocd/config/interface/sheevaplug.cfg“ im SheevaInstaller-Ordner nach
-~~~
+```sh
interface ft2232
ft2232_layout sheevaplug
ft2232_vid_pid 0×0403 0×6010
#ft2232_vid_pid 0x9e88 0x9e8f
#ft2232_device_desc “SheevaPlug JTAGKey FT2232D B”
jtag_khz 2000
-~~~
-{: .language-sh}
+```
umändern.
Wenn Debian jetzt auf dem SheevaPlug läuft und man sich über SSH einloggen konnte (pwd: nosoup4u), sollte man als erstes ein Update machen.
diff --git a/source/00_content/articles/2010-02-24_traffic_ueberwachung_mit_vnstat.md b/source/00_content/articles/2010-02-24_traffic_ueberwachung_mit_vnstat.md
index 309852c..9178cab 100644
--- a/source/00_content/articles/2010-02-24_traffic_ueberwachung_mit_vnstat.md
+++ b/source/00_content/articles/2010-02-24_traffic_ueberwachung_mit_vnstat.md
@@ -3,7 +3,7 @@
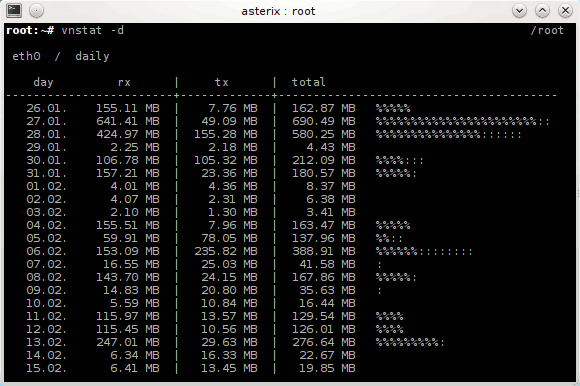
Heute möchte ich euch ein kleines und praktisches Programm zum Überwachen des Netzwerkverkehrs vorstellen: [vnstat](http://humdi.net/vnstat/).
vnStat ist ein konsolenbasierter Netzwerkverkehrmonitor der Logs mit der Menge des Datenverkehrs auf beliebigen Netzwerkschnittstellen speichert. Aus diesen Logs generiert vnStat dann diverse Statistiken.
-{: .full}
+{.full}
Installieren kann man vnstat unter Debian bequem aus den Paketquellen mit `apt-get install vnstat` oder unter ArchLinux mit `pacman -S vnstat`. Gestartet wird vnStat mit `vnstat`. Sobald der Daemon läuft schreibt vnstat den aktuellen Netzwerkverkehr in eine Datenbank. Durch Anhängen von Argumenten kann man jetzt schöne Statistiken auf der Konsole ausgeben, z.B. eine Statistik über die letzten Tage mit `vnstat -d` (siehe Bild) oder über die letzten Wochen mit `vnstat -w`. Eine Übersicht über alle möglichen Argumente bekommt man wie Üblich über `vnstat –help`. Eine sehr Interessante Funktion wie ich finde ist die Möglichkeit zur live-Anzeige des Verkehrs mit `vnstat -h`.
diff --git a/source/00_content/articles/2010-07-12_ocr_und_automatische_uebersetzung_mit_dem_n900.md b/source/00_content/articles/2010-07-12_ocr_und_automatische_uebersetzung_mit_dem_n900.md
index 150f747..7ccc7ec 100644
--- a/source/00_content/articles/2010-07-12_ocr_und_automatische_uebersetzung_mit_dem_n900.md
+++ b/source/00_content/articles/2010-07-12_ocr_und_automatische_uebersetzung_mit_dem_n900.md
@@ -2,15 +2,15 @@
Heute bin ich auf einem Streifzug durch das Maemo5 testing-Repository auf ein sehr praktisches Programm gestoßen: PhotoTranslator. Mit ihm lässt sich der Text aus Bildern extrahieren und mittels Google-Translate übersetzen.
-{: .full width="600px"}
+{.full width="600px"}
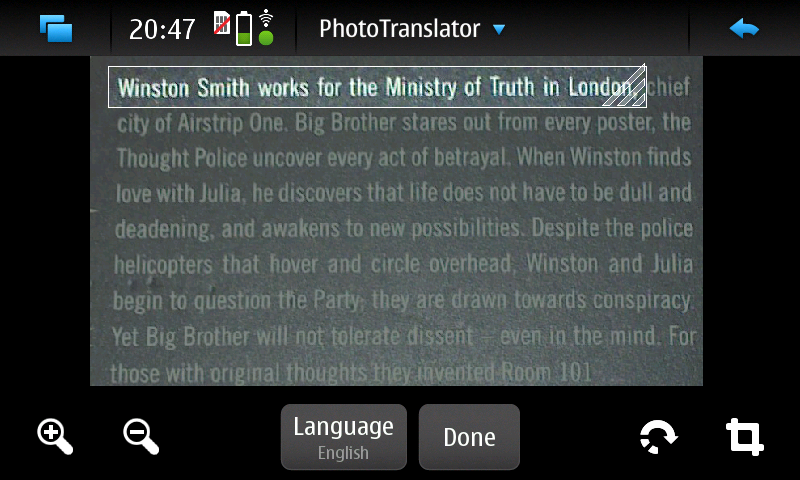
Das ist z.B. praktisch um fremdsprachige Speisekarten o.ä. in die eigene Sprache zu übersetzen. Nachdem man ein Bild ausgewählt oder direkt aus dem Programm heraus eines erstellt hat (funktioniert in der aktuellen Alpha-Version von PhotoTranslator noch nicht richtig) muss man als erstes den gewünschten Textteil mittels eines Rahmens, wie man ihn auch zum Zuschneiden von Fotos im Bildbetrachter des N900 verwendet auswählen – zur Zeit geht das jedoch leider nur mit einzelnen Zeilen und nicht mit ganzen Textblöcken.
-{: .full width="600px"}
+{.full width="600px"}
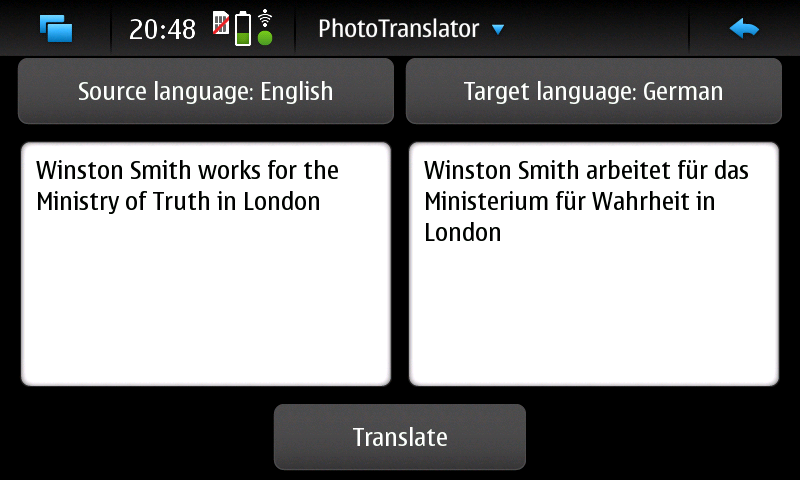
Danach muss man nurnoch die Ausgangs und Zielsprache wählen, kurz warten und schon bekommt man den eingescannten Ausgangstext und die Übersetzung präsentiert. Das funktioniert auch schon in dieser frühen Alpha-Version sehr gut.
-{: .full width="600px"}
+{.full width="600px"}
PhotoTranslator lässt sich aber nicht nur zum Übersetzen von Bildern, sondern auch als einfache Oberfläche für Google-Translate mit Texteingabe über die Tastatur verwenden.
Weitere Informationen und ein Demo-Video findet ihr unter [cybercomchannel.com](http://www.cybercomchannel.com/?p=63). Installieren lässt sich PhotoTranslator bei aktivierten extras-testing Repositories bequem aus der Paketverwaltung des N900 heraus.
diff --git a/source/00_content/articles/2011-03-31_sheevaplug_ueberwachung.md b/source/00_content/articles/2011-03-31_sheevaplug_ueberwachung.md
index 89ac393..311f34c 100644
--- a/source/00_content/articles/2011-03-31_sheevaplug_ueberwachung.md
+++ b/source/00_content/articles/2011-03-31_sheevaplug_ueberwachung.md
@@ -4,15 +4,14 @@ Um den Überblick über die Auslastung und den Traffic meines SheevaPlugs zu beh
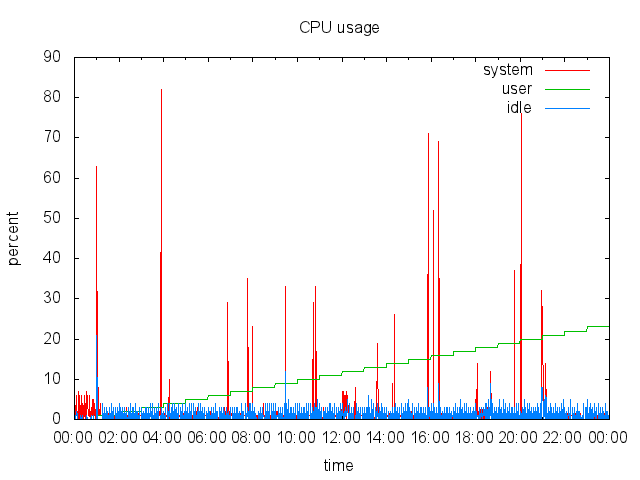
Den Systemmonitor Conky lasse ich mit dem Befehl `ssh -X -vv -Y -p 22 adrian@asterix "conky -c /home/adrian/.conkyrc"` über X-forwarding in meiner XFCE-Session anzeigen. Das klappt einwandfrei und ergibt zusammen mit dieser [Conky-Konfiguration](http://adrianktools.redirectme.net/files/.conkyrc) und einer lokalen Conky-Instanz folgendes Bild:
-{: .full}
+{.full}
Zusätzlich loggt der SheevaPlug regelmäßig die aktuellen Systemdaten wie CPU-Auslastung, Netzwerkverkehr und belegten Arbeitsspeicher und generiert sie zu Graphen die mir dann jede Nacht per eMail zugesand werden.
Zum Loggen der Daten verwende ich dstat das mit folgendem, von einem Cron-Job gestarteten Befehl aufgerufen wird:
-~~~
+```sh
dstat -tcmn 2 1 | tail -1 >> /var/log/systat.log
-~~~
-{: .language-sh}
+```
Die Argumente -tcmn geben hierbei die zu loggenden Systemdaten und deren Reihenfolge an – heraus kommen Zeilen wie diese:
@@ -20,7 +19,7 @@ Die Argumente -tcmn geben hierbei die zu loggenden Systemdaten und deren Reihenf
Um 0 Uhr wird dann die Log-Datei von einem Cron-Job mit diesem Script wegkopiert, Graphen werden von gnuplot generiert und dann mit einem kleinen Python-Programm versendet.
-~~~
+```sh
#!/bin/sh
mv /var/log/systat.log /root/sys_graph/stat.dat
cd /root/sys_graph/
@@ -28,12 +27,11 @@ cd /root/sys_graph/
./generate_memory.plot
./generate_network.plot
./send_report.py
-~~~
-{: .language-sh}
+```
Hier das gnuplot-Script zur Erzeugung des CPU-Graphen als Beispiel:
-~~~
+```sh
#!/usr/bin/gnuplot
set terminal png
set output "cpu.png"
@@ -46,12 +44,11 @@ set format x "%H:%M"
plot "stat.dat" using 1:4 title "system" with lines, \
"stat.dat" using 1:3 title "user" with lines, \
"stat.dat" using 1:5 title "idle" with lines
-~~~
-{: .language-sh}
+```
… und hier noch das Python-Programm zum Versenden per Mail:
-~~~
+```python
#!/usr/bin/python2
import smtplib
from time import *
@@ -82,12 +79,11 @@ s.login('mail@mail.mail', '#####')
s.sendmail('mail@mail.mail', 'mail@mail.mail', msg.as_string())
s.quit()
-~~~
-{: .language-python}
+```
Als Endergebniss erhalte ich dann täglich solche Grafiken per Mail:
-{: .full .clear}
+{.full .clear}
Ich finde es immer wieder erstaunlich mit wie wenigen Zeilen Quelltext man interessante Sachen unter Linux erzeugen kann – oder besser wie viel Programme wie gnuplot mit nur wenigen Anweisungen erzeugen können. So hat das komplette Schreiben dieser Scripts mit Recherche nur etwa 1,5 Stunden gedauert – inklusive Testen.
Alle verwendeten Programme sind in den ArchLinux Paketquellen vorhanden – auch in denen von PlugBox-Linux, einer Portierung von ArchLinux auf ARM-Plattformen die ich nur immer wieder empfehlen kann – besonders nach den jetzt oft erscheinenden Paket-Updates. Aber dazu auch dieser Artikel: [Plugbox Linux – Ein ArchLinux Port für den SheevaPlug](/article/plugbox_linux_ein_archlinux_port_fuer_den_sheevaplug/).
diff --git a/source/00_content/articles/2011-06-14_darstellen_von_gps_daten_mit_gnuplot.md b/source/00_content/articles/2011-06-14_darstellen_von_gps_daten_mit_gnuplot.md
index cc97add..28c95de 100644
--- a/source/00_content/articles/2011-06-14_darstellen_von_gps_daten_mit_gnuplot.md
+++ b/source/00_content/articles/2011-06-14_darstellen_von_gps_daten_mit_gnuplot.md
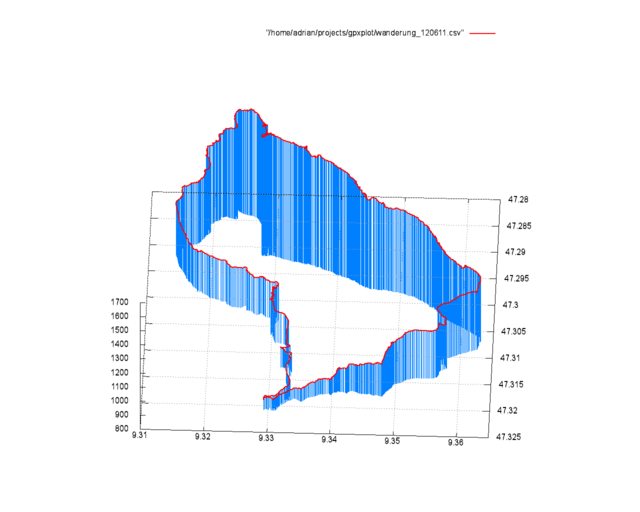
@@ -4,19 +4,18 @@ Bei meiner letzten Wanderung in den Schweizer Alpen habe ich spaßeshalber das N
Die Daten der Messpunkte sind im XML als `trkpt`-Tags gespeichert. Enthalten sind jeweils der Längen- und Breitengrad, die Uhrzeit, der Modus (3d / 2d), die Höhe über Null und die Anzahl der zur Positionsbestimmung genutzten Satelliten. Aussehen tut das ganze dann z.B. so:
-~~~
+```xml
3d8706
-~~~
-{: .language-xml}
+```
Diese Daten lassen sich nun sehr einfach Verarbeiten – ich habe das Python `xml.dom.minidom` Modul verwendet. Um die Positionen einfacher verwenden zu können, werden sie mit dieser Funktion in Listenform gebracht:
-~~~
+```python
def getPositions(xml):
doc = minidom.parse(xml)
node = doc.documentElement
@@ -29,12 +28,11 @@ def getPositions(xml):
pos["ele"] = int(TrkPt.getElementsByTagName("ele")[0].childNodes[0].nodeValue)
positions.append(pos)
return positions
-~~~
-{: .language-python}
+```
Aus dieser Liste kann ich jetzt schon einige Kennzahlen ziehen:
-~~~
+```python
def printStats(gpxPositions):
highEle = gpxPositions[0]["ele"]
lowEle = gpxPositions[0]["ele"]
@@ -48,8 +46,7 @@ def printStats(gpxPositions):
print "Lowest elevation: " + str(lowEle)
print "Highest elevation: " + str(highEle)
print "Height difference: " + str(eleDiv)
-~~~
-{: .language-python}
+```
Die Kennzahlen für meine Testdaten wären:
@@ -61,21 +58,20 @@ Die Kennzahlen für meine Testdaten wären:
Da die Daten ja, wie schon im Titel angekündigt, mit gnuplot dargestellt werden sollen werden sie mit dieser Funktion in für gnuplot lesbares CSV gebracht:
-~~~
+```python
def printCsv(gpxPositions):
separator = ';'
for pos in gpxPositions:
print pos["lat"] + separator + pos["lon"] + separator + str(pos["ele"])
-~~~
-{: .language-python}
+```
## Plotten mit gnuplot
-{: .full .clear}
+{.full .clear}
Eine solche, dreidimensionale Ausgabe der GPS Daten zu erzeugen ist mit der `splot`-Funktion sehr einfach.
-~~~
+```sh
#!/usr/bin/gnuplot
set terminal png size 1280,1024
set output "output.png"
@@ -90,16 +86,14 @@ set datafile separator ';'
splot "/home/adrian/projects/gpxplot/wanderung_120611.csv" with impulses lt 3 lw 1
splot "/home/adrian/projects/gpxplot/wanderung_120611.csv" with lines lw 2
unset multiplot
-~~~
-{: .language-sh}
+```
Mit `set terminal png size 1280,1024` und `set output "output.png"` werden zuerst das Ausgabemedium, die Größe und der Dateiname der Ausgabe definiert. Dannach aktiviert `set multiplot` den gnuplot-Modus, bei dem mehrere Plots in einer Ausgabe angezeigt werden können. Dieses Verhalten brauchen wir hier, um sowohl die Strecke selbst als rote Line, als auch die zur Verdeutlichung verwendeten blauen Linien gleichzeitig anzuzeigen.
Mit `set [y,x,z]range` werden die Außengrenzen des zu plottenden Bereichs gesetzt. Dies ließe sich natürlich auch über ein Script automatisch erledigen. Als Nächstes wird mit `set view 28,272,1,1` die Blickrichtung und Skalierung definiert. `set ticslevel 0` sorgt dafür, dass die Z-Achse direkt auf der Grundebene beginnt. Um ein Gitter auf der Grundfläche anzuzeigen, gibt es `set grid`.
Als letztes werden jetzt die zwei Plots mit `splot` gezeichnet. Die Angaben hinter `with` steuern hierbei das Aussehen der Linien.
-Falls jemand den Artikel mit meinen Daten nachvollziehen möchte - das GPX-File kann hier heruntergeladen werden:
- [2011-06-12.gpx](https://static.kummerlaender.eu/media/2011-06-12.gpx)
+Falls jemand den Artikel mit meinen Daten nachvollziehen möchte - das GPX-File kann hier heruntergeladen werden: [2011-06-12.gpx](https://static.kummerlaender.eu/media/2011-06-12.gpx)
Zum Schluss hier noch ein Blick vom Weg auf den Kronberg Richtung Jakobsbad im Appenzell:
-{: .full}
+{.full}
diff --git a/source/00_content/articles/2011-09-03_die_sache_mit_dem_netzteil.md b/source/00_content/articles/2011-09-03_die_sache_mit_dem_netzteil.md
index c96d7d5..4da8fdb 100644
--- a/source/00_content/articles/2011-09-03_die_sache_mit_dem_netzteil.md
+++ b/source/00_content/articles/2011-09-03_die_sache_mit_dem_netzteil.md
@@ -2,6 +2,6 @@
Diese Woche hat meinen SheevaPlug das selbe Schicksal getroffen wie viele andere auch – nach dem Urlaub war das Netzteil kaputt. Mit einem externen von [Conrad](http://www.conrad.de/ce/de/product/510820/Dehner-SYS1308-Netzt-fests-5V15W%22%22) geht er jetzt aber wieder einwandfrei.
-{: .full}
+{.full}
Als sehr nützlich, um in der Zeit bis der Plug repariert war wenigstens eine _Netzteil-Kaputt_-Meldung auf der Webseite anzeigen zu können, erwies sich [Staticloud](http://staticloud.com) – ein netter Webservice um statische Webseiten per drag ‘n drop kostenlos in der Amazon-Cloud hosten zu können. Um die Inhalte zugänglich zu halten (Backup habe ich natürlich schon – aber bis jetzt nur als MySQL-Dump, ab jetzt wohl auch das ganze als HTML ) half mir Google – der gesammte Blog hängt praktischerweise dort im Cache.
diff --git a/source/00_content/articles/2011-10-01_lighttpd_konfiguration_fuer_symphony.md b/source/00_content/articles/2011-10-01_lighttpd_konfiguration_fuer_symphony.md
index fade6af..90fa82e 100644
--- a/source/00_content/articles/2011-10-01_lighttpd_konfiguration_fuer_symphony.md
+++ b/source/00_content/articles/2011-10-01_lighttpd_konfiguration_fuer_symphony.md
@@ -4,14 +4,16 @@ Da ich die Neuauflage dieser Seite nicht mehr auf Wordpress, sondern auf dem [Sy
Von den im Netz verfügbaren [Beispielen](http://blog.ryara.net/2009/12/05/lighttpd-rewrite-rules-for-symphony-cms/) hat jedoch keines ohne Einschränkungen funktioniert. Aus diesem Grund habe ich auf Basis der oben verlinkten Konfiguration ein funktionierendes Regelwerk geschrieben:
- url.rewrite-once += (
- "^/favicon.ico$" => "$0",
- "^/robots.txt$" => "$0",
- "^/symphony/(assets|content|lib|template)/.*$" => "$0",
- "^/workspace/([^?]*)" => "$0",
- "^/symphony(\/(.*\/?))?(.*)\?(.*)$" => "/index.php?symphony-page=$1&mode=administration&$4&$5",
- "^/symphony(\/(.*\/?))?$" => "/index.php?symphony-page=$1&mode=administration",
- "^/([^?]*/?)(\?(.*))?$" => "/index.php?symphony-page=$1&$3"
- )
+```
+url.rewrite-once += (
+ "^/favicon.ico$" => "$0",
+ "^/robots.txt$" => "$0",
+ "^/symphony/(assets|content|lib|template)/.*$" => "$0",
+ "^/workspace/([^?]*)" => "$0",
+ "^/symphony(\/(.*\/?))?(.*)\?(.*)$" => "/index.php?symphony-page=$1&mode=administration&$4&$5",
+ "^/symphony(\/(.*\/?))?$" => "/index.php?symphony-page=$1&mode=administration",
+ "^/([^?]*/?)(\?(.*))?$" => "/index.php?symphony-page=$1&$3"
+)
+```
Dieses läuft mit der aktuellsten Symphony Version einwandfrei. Zu finden ist die Konfiguration übrigens mit den restlichen Quellen meines neuen Webseiten-Setups auf [Github](https://github.com/KnairdA/blog.kummerlaender.eu).
diff --git a/source/00_content/articles/2011-10-02_tarsnap_backups_fuer_paranoide.md b/source/00_content/articles/2011-10-02_tarsnap_backups_fuer_paranoide.md
index 7aedf41..d3dca15 100644
--- a/source/00_content/articles/2011-10-02_tarsnap_backups_fuer_paranoide.md
+++ b/source/00_content/articles/2011-10-02_tarsnap_backups_fuer_paranoide.md
@@ -4,23 +4,29 @@ Für meine Backups nutze ich jetzt seit einiger Zeit den Online-Service [Tarsnap
Das ganze ist so aufgebaut, dass immer nur veränderte und neue Dateien übertragen werden müssen. Alle Daten werden schon vom Client verschlüsselt, sodass keine unverschlüsselten Daten übers Netzwerk fließen und weder die Entwickler von Tarsnap noch Amazon den Inhalt der Daten auslesen können.
-Der Service ist nicht kostenlos, aber sehr günstig - der Preis pro Byte Speicher / Datenverkehr beträgt 300 Picodollar, ein Gigabyte kostet also pro Monat nur 0,30$.
+Der Service ist nicht kostenlos, aber sehr günstig - der Preis pro Byte Speicher / Datenverkehr beträgt 300 Picodollar, ein Gigabyte kostet also pro Monat nur 0,30 Dollar.
Der Tarsnap-Client ist im Quellcode verfügbar (aber nicht unter einer Open Source Lizenz) und lässt sich problemlos auch auf ARM Prozessoren kompilieren, sodass ich auch vom N900 und SheevaPlug aus Zugriff auf meine Backups haben kann. Die Authentifizierung mit dem Server funktioniert über einen Schlüssel, der sich nach Eingabe des Passworts mit folgendem Befehl generieren lässt:
- tarsnap-keygen --keyfile [pfad-zum-schlüssel] --user [email] --machine [hostname]
+```sh
+tarsnap-keygen --keyfile [pfad-zum-schlüssel] --user [email] --machine [hostname]
+```
Die resultierende Datei ermöglicht ohne zusätzliche Authentifizierung Zugriff auf die Backups und sollte somit sicher aufbewahrt werden und nicht in falsche Hände geraten, denn ohne sie hat man keinen Zugriff mehr auf seine Daten.
Ein neues Backup lässt sich über diesen Befehl anlegen:
- tarsnap -c -f [name-des-backups] [zu-sichernder-pfad]
+```sh
+tarsnap -c -f [name-des-backups] [zu-sichernder-pfad]
+```
Jedes weitere Backup geht danach um einiges schneller weil Tarsnap nur veränderte Daten überträgt. Standardmäßig wird dieser Cache unter "/usr/local/tarsnap-cache" und der Schlüssel unter "/root/tarsnap.key" erwartet, dies lässt sich jedoch über entsprechende Parameter steuern - näheres dazu findet sich auf der [Manpage](http://www.tarsnap.com/man-tarsnap.1.html).
Sollte man dann einmal in die nicht wünschenswerte Situation kommen Zugriff auf sein Backup zu benötigen, reicht dieser Befehl um die Daten wiederherzustellen:
- tarsnap -x -f [name-des-backups] [wiederherzustellender-pfad]
+```sh
+tarsnap -x -f [name-des-backups] [wiederherzustellender-pfad]
+```
Tarsnap kann ich wirklich empfehlen, es hat mich vom [Konzept](http://www.tarsnap.com/design.html) und der Umsetzung her voll überzeugt und ist auf jeden Fall eine ernst zunehmende Alternative zu anderen Backuplösungen in der _Wolke_.
diff --git a/source/00_content/articles/2011-10-16_kurztipp_n900_retten_ohne_neu_zu_flashen.md b/source/00_content/articles/2011-10-16_kurztipp_n900_retten_ohne_neu_zu_flashen.md
index f59b709..4084d69 100644
--- a/source/00_content/articles/2011-10-16_kurztipp_n900_retten_ohne_neu_zu_flashen.md
+++ b/source/00_content/articles/2011-10-16_kurztipp_n900_retten_ohne_neu_zu_flashen.md
@@ -7,9 +7,8 @@ Erst sah es so aus, als würde ich nicht darum herum kommen das Betriebsystem ne
Dabei handelt es sich um ein kleines Linux welches mithilfe des normalen [Flashers](http://tablets-dev.nokia.com/maemo-dev-env-downloads.php) direkt in den RAM des N900 kopiert und dort gebootet werden kann. Vom rescueOS aus kann man dann das Root-Dateisystem problemlos einbinden und Probleme beheben. Zum Starten reicht das [initrd Image](http://n900.quitesimple.org/rescueOS/rescueOS-1.0.img) und folgender Befehl:
-~~~
+```sh
flasher-3.5 -k 2.6.37 -n initrd.img -l -b"rootdelay root=/dev/ram0"
-~~~
-{: .language-sh}
+```
Nähere Informationen zur Verwendung und den Funktionen finden sich in der rescueOS [Dokumentation](http://n900.quitesimple.org/rescueOS/documentation.txt).
diff --git a/source/00_content/articles/2011-11-08_informationen_umformen_mit_xsl.md b/source/00_content/articles/2011-11-08_informationen_umformen_mit_xsl.md
index 7785b83..f84f17c 100644
--- a/source/00_content/articles/2011-11-08_informationen_umformen_mit_xsl.md
+++ b/source/00_content/articles/2011-11-08_informationen_umformen_mit_xsl.md
@@ -8,7 +8,7 @@ Schlussendlich habe ich dann eine [XSLT](http://de.wikipedia.org/wiki/XSLT) gesc
Mit XSL lassen sich XML Dateien in andere Formen bringen. Da Mediawiki mehr oder weniger valides XHTML ausgibt, kann man, nachdem das XHTML mit [Tidy](http://tidy.sourceforge.net) ein wenig aufgeräumt wurde, sehr einfach die [Terminliste](http://wiki.piratenpartei.de/BW:Kreisverband_Konstanz/Termine) extrahieren und gleichzeitig in RSS umformen:
-~~~
+```xsl
-~~~
-{: .language-xsl}
+```
Der Kern dieses XSL ist nicht mehr als ein Template welches auf den [XPATH](http://de.wikipedia.org/wiki/XPATH) zum Finden der Terminliste reagiert. Die For-Each-Schleife iteriert dann durch die Termine und formt diese entsprechend in RSS um.
Der einzige Knackpunkt kommt daher, dass XHTML kein normales XML ist und somit seinen eigenen Namespace hat. Diesen sollte man im Element `xsl:stylesheet` korrekt angeben, sonst funktioniert nichts. Auch muss im XPATH Ausdruck dann vor jedem Element ein `x:` eingefügt werden um dem XSL Prozessor den Namespace für das jeweilige Element mitzuteilen.
@@ -72,17 +71,16 @@ Zum Anpassen des Datums verwende ich - wie auch in diesem Blog - die [date-time.
Mit der eben beschriebenen XSLT lässt sich jetzt in drei Schritten das fertige RSS generieren:
-~~~
+```sh
#!/bin/sh
wget -O termine_wiki.html "http://wiki.piratenpartei.de/BW:Kreisverband_Konstanz/Termine"
tidy -asxml -asxhtml -O termine_tidy.html termine_wiki.html
xsltproc --output termine_kvkn.rss --novalid termine_kvkn.xsl termine_tidy.html
-~~~
-{: .language-sh}
+```
In PHP ist das ganze dann zusammen mit sehr einfachem Caching auch direkt auf einem Webserver einsetzbar:
-~~~
+```php
define('CACHE_TIME', 6);
define('CACHE_FILE', 'rss.cache');
@@ -139,5 +137,4 @@ function generate_rss()
return false;
}
}
-~~~
-{: .language-php}
+```
diff --git a/source/00_content/articles/2012-01-25_erfahrungen_mit_openslides.md b/source/00_content/articles/2012-01-25_erfahrungen_mit_openslides.md
index 2804605..b670400 100644
--- a/source/00_content/articles/2012-01-25_erfahrungen_mit_openslides.md
+++ b/source/00_content/articles/2012-01-25_erfahrungen_mit_openslides.md
@@ -6,13 +6,13 @@ OpenSlides ist ein auf dem Python-Webframework [Django](https://www.djangoprojec
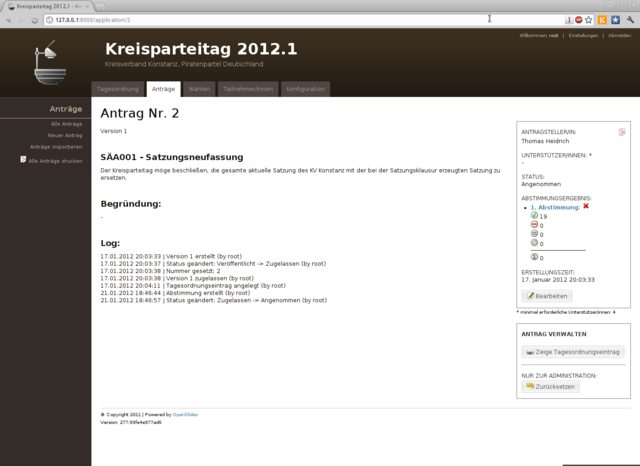
Das UI ist dabei in den Administrationsbereich, über den sämtliche Daten eingegeben werden können, und eine Beamer-Ansicht geteilt. Beide dieser Komponenten laufen in einem gewöhnlichen Webbrowser. Das Aussehen lässt sich also einfach durch Modifikation der Templates und der CSS-Formatierungen an die eigenen Wünsche anpassen.
-{: .full}
+{.full}
Nachdem ich anfangs alle Wahlen, bekannten Teilnehmer und Anträge in das Redaktionsystem eingespiesen hatte, ließ sich am Parteitag selbst dann mit wenigen Mausklicks eine ansprechende Präsentation des aktuellen Themas erzeugen.
Wahlergebnisse waren ebenso wie die Annahme oder Ablehnung eines Antrags über entsprechende Formulare schnell eingepflegt und dargestellt.
Sehr gefallen hat mir im Vorfeld auch die Möglichkeit der Generierung von Antragsbüchern als PDF.
-{: .full}
+{.full}
Der Funktionsumfang von OpenSlides geht jedoch über die bloße Darstellung der TO auf einem Beamer hinaus. So kann wenn gewünscht jeder Teilnehmer über sein eigenes Endgerät auf das Webinterface zugreifen und als Deligierter an der Versammlung teilnehmen - also Abstimmen, Wählen und Anträge stellen.
Theoretisch ermöglicht es diese Software also - bei entsprechender Authentifizierung - die Durchführung von dezentralen Versammlungen. Aber auch wenn dies z.B. aufgrund von zur Nachvollziehbarkeit nötiger Klarnamenspflicht nicht in Frage kommt, ergibt sich doch so für die Teilnehmer immerhin die Möglichkeit den Ablauf auf einem eigenen Gerät nachzuverfolgen.
@@ -20,7 +20,7 @@ Theoretisch ermöglicht es diese Software also - bei entsprechender Authentifizi
Der einzige Punkt der mich wirklich störte war die fehlende Anzeige von Wahlergebnissen der Teilnehmer die eine Wahl verloren hatten. Die jeweilige Stimmenzahl war im Frontend erst sichtbar nachdem der entsprechende Kandidat als Sieger markiert worden war.
Doch auch dieses Problem ließ sich - OpenSource sei Dank - schnell über manuelles Eingreifen im Quelltext korrigieren:
-~~~
+```diff
--- /home/adrian/Downloads/original_views.py
+++ /opt/hg.openslides.org/openslides/agenda/views.py
@@ -132,14 +132,11 @@
@@ -42,8 +42,7 @@ Doch auch dieses Problem ließ sich - OpenSource sei Dank - schnell über manuel
else:
tmplist[1].append("-")
votes.append(tmplist)
-~~~
-{: .language-diff}
+```
OpenSlides ist wirklich ein tolles Stück Software und ich kann nur jedem der vor der Aufgabe steht eine Versammlung zu organisieren, sei es die eines Vereins oder wie in meinem Fall die einer Partei, empfehlen sich es einmal näher anzusehen.
Weitere Angaben zur Installation und Konfiguration finden sich auf der [Webpräsenz](http://openslides.org/de/index.html) und im [Quell-Archiv](http://openslides.org/download/openslides-1.1.tar.gz).
diff --git a/source/00_content/articles/2012-04-07_mobile_endgeraete_und_freie_software.md b/source/00_content/articles/2012-04-07_mobile_endgeraete_und_freie_software.md
index 26d6435..8feba56 100644
--- a/source/00_content/articles/2012-04-07_mobile_endgeraete_und_freie_software.md
+++ b/source/00_content/articles/2012-04-07_mobile_endgeraete_und_freie_software.md
@@ -11,7 +11,7 @@ Geräte die auf Android als Betriebssystem setzen bieten natürlich prinzipiell
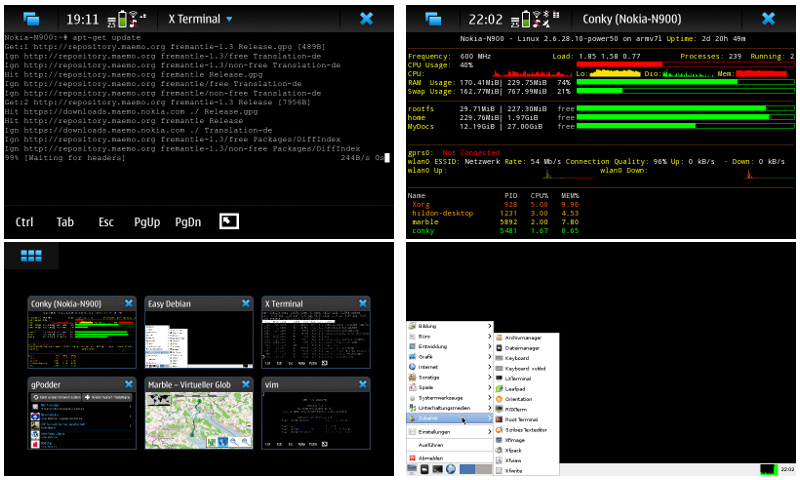
Glücklicherweise sind wir nicht ganz auf Android-ausführende Hardware beschränkt. Das Mobiltelefon meiner Wahl ist seit etwa 2 Jahren beispielsweise das [N900](http://en.wikipedia.org/wiki/Nokia_N900), das aus meiner Sicht wirklich als **das** offene Gerät auf dem Markt angesehen werden kann. Ich könnte hier jetzt seitenweise Punkte aufzählen was alles mit dem N900 möglich ist aber es geht auch kurz:
-{: .full width="600px"}
+{.full width="600px"}
Mit dem N900 lässt sich, ohne das man durch herstellerseitige Einschränkungen belästigt wird, alles machen was mit einem normalen Linux-Rechner geht. Die einzige mir bekannte Einschränkung ist: Teile der Hardware wie z.B. die Grafikkarte erfordern (noch) unfreie, geschlossene Treiber.
diff --git a/source/00_content/articles/2012-08-29_erfahrungen_mit_einer_ssd_unter_linux.md b/source/00_content/articles/2012-08-29_erfahrungen_mit_einer_ssd_unter_linux.md
index 7be6d2a..72ce8c0 100644
--- a/source/00_content/articles/2012-08-29_erfahrungen_mit_einer_ssd_unter_linux.md
+++ b/source/00_content/articles/2012-08-29_erfahrungen_mit_einer_ssd_unter_linux.md
@@ -21,7 +21,7 @@ nötig sein sollte ist das umso besser. Die 16 GiB SD-Karte des SheevaPlugs läu
Hier meine derzeitige `/etc/fstab`:
-~~~
+```sh
#
# /etc/fstab: static file system information
#
@@ -30,8 +30,7 @@ tmpfs /tmp tmpfs nodev,nosuid 0 0
/dev/sda1 swap swap defaults,noatime,discard 0 0
/dev/sda2 / ext4 defaults,noatime,discard,data=ordered 0 0
-~~~
-{: .language-sh}
+```
## Verschlüsselung?
diff --git a/source/00_content/articles/2012-11-20_virtualisierung_mit_kvm_und_virtuelle_netzwerke_mit_vde.md b/source/00_content/articles/2012-11-20_virtualisierung_mit_kvm_und_virtuelle_netzwerke_mit_vde.md
index a4b1924..8d3e8db 100644
--- a/source/00_content/articles/2012-11-20_virtualisierung_mit_kvm_und_virtuelle_netzwerke_mit_vde.md
+++ b/source/00_content/articles/2012-11-20_virtualisierung_mit_kvm_und_virtuelle_netzwerke_mit_vde.md
@@ -25,10 +25,9 @@ des Gast-Systems werden auf die gleiche Weise gesetzt. Aus diesem Grund gehe ich
Hier als Beispiel mein derzeitiger Standardaufruf von KVM, der für alle VMs gleich ist. Dynamisch ist allein das zu verwendende Speicher-Gerät - in meinem Fall verschiedene Image-Dateien.
-~~~
+```sh
qemu-kvm -cpu host -hda $1 -m 1024 -daemonize -vnc none -usb -net nic -net vde
-~~~
-{: .language-sh}
+```
Dieser verwendet das als erster Parameter übergebene Gerät als Festplatte und setzt neben den nötigen Netzwerk-Einstellungen die VM mittels `-daemonize` in den Hintergrund. Falls benötigt, kann
als Wert des Parameters `-vnc` auch eine von einem Doppelpunkt angeführte Zahl übergeben werden um die Grafik-Ausgabe der VM an einen VNC-Server anzubinden (z.B. `-vnc :1` für `127.0.0.1:1`). Diese
@@ -40,7 +39,7 @@ Funktion verwende ich nicht, da ich ausschließlich über das interne Netzwerk d
Meine Konfiguration hält sich dabei im wesentlichen an den [Vorschlag](https://wiki.archlinux.org/index.php/QEMU#Networking_with_VDE2) im englischen Arch-Wiki, welchen ich in ein einfaches Script verpackt habe:
-~~~
+```sh
#!/bin/sh
case "$1" in
start)
@@ -55,8 +54,7 @@ case "$1" in
ip tuntap del tap0 mode tap
;;
esac
-~~~
-{: .language-sh}
+```
Dieses Script erzeugt ein virtuelles Interface `tap0` und verbindet ein neues, als Daemon im Hintergrund laufendes, virtuelles Switch mit diesem. Als nächstes wird dann noch eine statische IP Konfiguration für das virtuelle Interface definiert. Durch diese können alle mit `-net nic -net vde` Parametern gestarteten KVM Gäste über die IP `192.168.100.254` auf den Host zugreifen.
@@ -70,7 +68,7 @@ In den Gast-Systemen selbst muss zusätzlich eine statische IP Konfiguration vor
Um das interne virtuelle LAN bei Bedarf mit der Außenwelt zu verbinden gibt es ebenfalls ein kleines Script welches die nötige Route erzeugt bzw. löscht:
-~~~
+```sh
#!/bin/sh
case "$1" in
start)
@@ -82,8 +80,7 @@ case "$1" in
echo "0" > /proc/sys/net/ipv4/ip_forward
;;
esac
-~~~
-{: .language-sh}
+```
Anpassbar ist hierbei das Interface, um z.B. daheim `eth0` und unterwegs wahlweise `wlan0` oder `usb0` verwenden zu können.
@@ -91,38 +88,39 @@ Anpassbar ist hierbei das Interface, um z.B. daheim `eth0` und unterwegs wahlwei
Nach einer Kernel Aktualisierung im ArchLinux Gast-System, kam es beim Neustart plötzlich zu dieser etwas erschreckenden Meldung:
- KVM: entry failed, hardware error 0x80000021
-
- If you're running a guest on an Intel machine without unrestricted mode
- support, the failure can be most likely due to the guest entering an invalid
- state for Intel VT. For example, the guest maybe running in big real mode
- which is not supported on less recent Intel processors.
-
- EAX=00000000 EBX=0020fa5c ECX=00000000 EDX=fffff000
- ESI=f6d29014 EDI=00000001 EBP=f6461fa0 ESP=f6461f60
- EIP=c0128443 EFL=00010246 [---Z-P-] CPL=0 II=0 A20=1 SMM=0 HLT=0
- ES =007b 00000000 ffffffff 00c0f300 DPL=3 DS [-WA]
- CS =0060 00000000 ffffffff 00c09b00 DPL=0 CS32 [-RA]
- SS =0068 00000000 ffffffff 00c09300 DPL=0 DS [-WA]
- DS =007b 00000000 ffffffff 00c0f300 DPL=3 DS [-WA]
- FS =00d8 36648000 ffffffff 00809300 DPL=0 DS16 [-WA]
- GS =00e0 f6d2f540 00000018 00409100 DPL=0 DS [--A]
- LDT=0000 ffff0000 f0000fff 00f0ff00 DPL=3 CS64 [CRA]
- TR =0080 f6d2d3c0 0000206b 00008b00 DPL=0 TSS32-busy
- GDT= f6d28000 000000ff
- IDT= c060b000 000007ff
- CR0=8005003b CR2=ffffffff CR3=006ef000 CR4=000006d0
- DR0=0000000000000000 DR1=0000000000000000 DR2=0000000700000000 DR3=0000000000000000
- DR6=00000000ffff0ff0 DR7=0000000000000400
- EFER=0000000000000000
- Code=00 8b 15 c4 b5 61 c0 55 89 e5 5d 8d 84 10 00 c0 ff ff 8b 00 8d b6 00 00 00 00 8d bf 00 00 00 00 8b 15 a0 ae 61 c0 55 89 e5 53 89 c3 b8 30 00 00 00
+```
+KVM: entry failed, hardware error 0x80000021
+
+If you're running a guest on an Intel machine without unrestricted mode
+support, the failure can be most likely due to the guest entering an invalid
+state for Intel VT. For example, the guest maybe running in big real mode
+which is not supported on less recent Intel processors.
+
+EAX=00000000 EBX=0020fa5c ECX=00000000 EDX=fffff000
+ESI=f6d29014 EDI=00000001 EBP=f6461fa0 ESP=f6461f60
+EIP=c0128443 EFL=00010246 [---Z-P-] CPL=0 II=0 A20=1 SMM=0 HLT=0
+ES =007b 00000000 ffffffff 00c0f300 DPL=3 DS [-WA]
+CS =0060 00000000 ffffffff 00c09b00 DPL=0 CS32 [-RA]
+SS =0068 00000000 ffffffff 00c09300 DPL=0 DS [-WA]
+DS =007b 00000000 ffffffff 00c0f300 DPL=3 DS [-WA]
+FS =00d8 36648000 ffffffff 00809300 DPL=0 DS16 [-WA]
+GS =00e0 f6d2f540 00000018 00409100 DPL=0 DS [--A]
+LDT=0000 ffff0000 f0000fff 00f0ff00 DPL=3 CS64 [CRA]
+TR =0080 f6d2d3c0 0000206b 00008b00 DPL=0 TSS32-busy
+GDT= f6d28000 000000ff
+IDT= c060b000 000007ff
+CR0=8005003b CR2=ffffffff CR3=006ef000 CR4=000006d0
+DR0=0000000000000000 DR1=0000000000000000 DR2=0000000700000000 DR3=0000000000000000
+DR6=00000000ffff0ff0 DR7=0000000000000400
+EFER=0000000000000000
+Code=00 8b 15 c4 b5 61 c0 55 89 e5 5d 8d 84 10 00 c0 ff ff 8b 00 8d b6 00 00 00 00 8d bf 00 00 00 00 8b 15 a0 ae 61 c0 55 89 e5 53 89 c3 b8 30 00 00 00
+```
Dies sah für mich im ersten Moment wie ein klarer Hardware-Fehler aus, alle Informationen die sich über meine bevorzugte Suchmaschine finden ließen, waren jedoch für andere Situationen und ältere Kernel Versionen als `3.6.6-1`. Nach Tests mit verschiedenen Parametern für die zuständigen Kernel-Module, funktionierte es schließlich nach Laden des Moduls mit folgendem Befehl wieder einwandfrei:
-~~~
+```sh
modprobe kvm_intel emulate_invalid_guest_state=0
-~~~
-{: .language-sh}
+```
Um den `emulate_invalid_guest_state` Parameter dauerhaft zu setzen reicht ein Eintrag in `/etc/modprobe.d`.
diff --git a/source/00_content/articles/2013-04-27_declaring_functions_local_to_a_translation_unit_in_cpp.md b/source/00_content/articles/2013-04-27_declaring_functions_local_to_a_translation_unit_in_cpp.md
index ae04631..be0e41c 100644
--- a/source/00_content/articles/2013-04-27_declaring_functions_local_to_a_translation_unit_in_cpp.md
+++ b/source/00_content/articles/2013-04-27_declaring_functions_local_to_a_translation_unit_in_cpp.md
@@ -2,27 +2,25 @@
In a current project of mine I defined the following function marked with the inline hint without declaring it in a header file:
-~~~
+```cpp
inline bool checkStorageSection(const void* keyBuffer) {
return (StorageSection::Edge == readNumber(
reinterpret_cast(keyBuffer)+0
));
}
-~~~
-{: .language-cpp}
+```
This function was not defined in one but in multiple translation units - each instance with the same signature but a slightly different comparison contained in the function body. I expected these functions to be local to their respective translation unit and in the best case to be inlined into their calling member methods.
While debugging another issue that seemed to be unrelated to these functions I noticed a strange behaviour: The calls in the member methods that should have linked to their respective local function definition all linked to the same definition in a different translation unit (the one displayed above). A quick check in GDB using the _x_-command to display the function addresses confirmed this suspicion:
-~~~
+```gdb
// Function address in translation unit A
0x804e718 : 0x83e58955
// Function address in translation unit B
0x804e718 : 0x83e58955
-~~~
-{: .language-gdb}
+```
The address _0x804e718_ was the address of the function definition in translation unit "A" in both cases. At first I suspected that the cause was probably that both definitions were located in the same namespace, but excluding them from the enclosing namespace declaration did not fix the problem.
diff --git a/source/00_content/articles/2013-10-06_notizen_zu_cpp_und_unicode.md b/source/00_content/articles/2013-10-06_notizen_zu_cpp_und_unicode.md
index e900a66..0238df3 100644
--- a/source/00_content/articles/2013-10-06_notizen_zu_cpp_und_unicode.md
+++ b/source/00_content/articles/2013-10-06_notizen_zu_cpp_und_unicode.md
@@ -11,10 +11,9 @@ Getreu der auf [UTF-8 Everywhere](http://www.utf8everywhere.org/) hervorgebracht
Grundsätzlich stellt es auf der Plattform meiner Wahl - Linux mit Lokalen auf _en\_US.UTF-8_ - kein Problem dar, UTF-8 enkodierte Strings in C++ Programmen zu verarbeiten.
Den Klassen der C++ Standard Library ist es, solange wir nur über das reine Speichern und Bewegen von Strings sprechen, egal ob dieser in UTF-8, ASCII oder einem ganz anderen Zeichensatz kodiert ist. Möchten wir sicher gehen, dass ein in einer Instanz von _std::string_ enthaltener Text tatsächlich in UTF-8 enkodiert wird und dies nicht vom Zeichensatz der Quelldatei abhängig ist, reicht es dies durch voranstellen von _u8_ zu definieren:
-~~~
+```cpp
std::string test(u8"Hellø Uni¢ød€!");
-~~~
-{: .language-cpp}
+```
Der C++ Standard garantiert uns, dass ein solcher String in UTF-8 enkodiert wird. Auch die Ausgabe von in dieser Form enkodierten Strings funktioniert nach meiner Erfahrung - z.T. erst nach setzen der Lokale mittels _std::setlocale_ - einwandfrei. Probleme gibt es dann, wenn wir den Text als solchen näher untersuchen oder sogar verändern wollen bzw. die Ein- und Ausgabe des Textes in anderen Formaten erfolgen soll. Für letzteres gibt es eigentlich die _std::codecvt_ Facetten, welche aber in der aktuellen Version der GNU libstdc++ noch [nicht implementiert](http://gcc.gnu.org/onlinedocs/libstdc++/manual/status.html#status.iso.2011) sind.
Wir müssen in diesem Fall also auf externe Bibliotheken wie beispielweise [iconv](https://www.gnu.org/software/libiconv/) oder [ICU](http://site.icu-project.org/) zurückgreifen. Auch die in der C++ Standard Library enthaltenen Templates zur String-Verarbeitung helfen uns bei Multibyte-Enkodierungen, zu denen auch UTF-8 zählt, nicht viel, da diese mit dem _char_ Datentyp und nicht mit Code-Points arbeiten. So liefert _std::string_ beispielsweise für einen UTF-8 enkodierten String, welcher nicht nur von dem in einer Code-Unit abbildbaren ASCII-Subset Gebrauch macht, nicht die korrekte Zeichenanzahl. Auch eine String-Iteration ist mit den Standard-Klassen nur Byte- und nicht Code-Point-Weise umsetzbar. Wir stehen also vor der Entscheidung eine weitere externe Bibliothek zu verwenden oder Programm-Intern vollständig auf UTF-32 zu setzen.
@@ -26,11 +25,12 @@ Um zumindest für rein lesende Zugriffe auf UTF-8 Strings nicht gleich eine Bibl
UTF-8 enkodiert die aktuell maximal 21 Bit eines Unicode Code-Points in bis zu vier Code-Units mit einer Länge von je einem Byte. Die verbleibenden
maximal 11 Bit werden dazu verwendet, Anfangs- und Fortsetzungs-Bytes eines Code-Points zu kennzeichnen und schon in der ersten Code-Unit zu definieren, in wie vielen Code-Units das aktuelle Symbol enkodiert ist.
-| Payload | Struktur |
-| 7 | `0xxxxxxx` |
-| 11 | `110xxxxx 10xxxxxx` |
-| 17 | `1110xxxx 10xxxxxx 10xxxxxx` |
-| 21 | `11110xxx 10xxxxxx 10xxxxxx 10xxxxxx` |
+Payload Struktur
+------- -------------------------------------
+7 `0xxxxxxx`
+11 `110xxxxx 10xxxxxx`
+17 `1110xxxx 10xxxxxx 10xxxxxx`
+21 `11110xxx 10xxxxxx 10xxxxxx 10xxxxxx`
In obenstehender Tabelle ist die in [RFC3629](http://tools.ietf.org/html/rfc3629) definierte Struktur der einzelnen Code-Units zusammen mit der jeweiligen Anzahl der Payload-Bits dargestellt.
Anhand der Tabelle können wir erkennen, dass die Rückwärtskompatibilität zu ASCII dadurch gewährleistet wird, dass alle Code-Points bis
@@ -38,7 +38,7 @@ einschließlich 127 im ersten Byte dargestellt werden können. Sobald in der ers
Zur Erkennung und Umformung der UTF-8 Code-Units verwenden wir in der _UTF8::CodepointIterator_-Klasse die folgenden, in stark typisierten Enums definierten, Bitmasken:
-~~~
+```cpp
enum class CodeUnitType : uint8_t {
CONTINUATION = 128, // 10000000
LEADING = 64, // 01000000
@@ -52,13 +52,12 @@ enum class CodePoint : uint8_t {
THREE = 15, // 00001111
FOUR = 7, // 00000111
};
-~~~
-{: .language-cpp}
+```
Bei tieferem Interesse lässt sich die Implementierung der UTF-8 Logik in der Quelldatei [codepoint_iterator.cc](https://github.com/KnairdA/CodepointIterator/blob/master/src/codepoint_iterator.cc) nachlesen.
Zusätzlich zu den in GoogleTest geschriebenen [Unit-Tests](https://github.com/KnairdA/CodepointIterator/blob/master/test.cc) sehen wir im folgenden noch ein einfaches Beispiel zur Verwendung des `UTF8::CodepointIterator` mit einem [Beispieltext](http://www.columbia.edu/~fdc/utf8/) in altnordischen Runen:
-~~~
+```cpp
std::string test(u8"ᛖᚴ ᚷᛖᛏ ᛖᛏᛁ ᚧ ᚷᛚᛖᚱ ᛘᚾ ᚦᛖᛋᛋ ᚨᚧ ᚡᛖ ᚱᚧᚨ ᛋᚨᚱ");
for ( UTF8::CodepointIterator iter(test.cbegin());
@@ -66,8 +65,7 @@ for ( UTF8::CodepointIterator iter(test.cbegin());
++iter ) {
std::wcout << static_cast(*iter);
}
-~~~
-{: .language-cpp}
+```
Die Dereferenzierung einer Instanz des Iterators produziert den aktuellen Code-Point als _char32\_t_, da dieser Datentyp garantiert vier Byte lang ist. Die Ausgabe eines solchen UTF-32 enkodierten Code-Points ist mir allerdings leider nur nach dem Cast in _wchar\_t_ gelungen. Dieser wird trotzdem nicht als Dereferenzierungs-Typ verwendet, da die Länge nicht fest definiert ist, sondern abhängig von der jeweiligen C++ Implementierung unterschiedlich sein kann. Dies stellt jedoch kein größeres Problem dar, da der Iterator für die interne Betrachtung von Strings und nicht zur Konvertierung für die Ausgabe gedacht ist.
diff --git a/source/00_content/articles/2013-11-03_mapping_binary_structures_as_tuples_using_template_metaprogramming.md b/source/00_content/articles/2013-11-03_mapping_binary_structures_as_tuples_using_template_metaprogramming.md
index 5c82f05..e2b4784 100644
--- a/source/00_content/articles/2013-11-03_mapping_binary_structures_as_tuples_using_template_metaprogramming.md
+++ b/source/00_content/articles/2013-11-03_mapping_binary_structures_as_tuples_using_template_metaprogramming.md
@@ -17,7 +17,7 @@ differences in endianness and In-place modification of the structure fields.
To be able to easily work with structure definitions using template metaprogramming I am relying on the standard library's [_std::tuple_](http://en.cppreference.com/w/cpp/utility/tuple)
template.
-~~~
+```cpp
template
class BinaryMapping {
public:
@@ -42,8 +42,7 @@ class BinaryMapping {
Tuple tuple_;
};
-~~~
-{: .language-cpp}
+```
This implementation of a template class _BinaryMapping_ provides _get_ and _set_ template methods for accessing values in a given binary buffer using the mapping provided by a given
Tuple template argument. The most notable element of this class is the usage of the _decltype_ keyword which was introduced in C++11. This keyword makes it easier to declare types
@@ -55,7 +54,7 @@ as its return type is also dependent on the template arguments.
As you may have noticed the above template class is not complete as I have not included a implementation of the _TupleReader::read_ method which does the actual work of mapping the binary
buffer as a tuple. This mapping is achieved by the following recursive template methods:
-~~~
+```cpp
struct TupleReader {
template
static inline typename std::enable_if<
@@ -77,8 +76,7 @@ struct TupleReader {
);
}
};
-~~~
-{: .language-cpp}
+```
Template metaprogramming in C++ offers a Turing-complete language which is fully executed during compilation. This means that any problem we may solve during the runtime of a _normal_ program
may also be solved during compilation using template metaprogramming techniques. This kind of programming is comparable to functional programming as we have to rely on recursion and pattern
@@ -106,7 +104,7 @@ is always available as a template argument.
The classes _TupleReader_ and _BinaryMapping_ are enough to map a binary structure as a _std::tuple_ instantiation like in the following example where I define a _TestRecord_ tuple containing
a pointer to _uint64\_t_ and _uint16\_t_ integers:
-~~~
+```cpp
typedef std::tuple TestRecord;
uint8_t* buffer = reinterpret_cast(
@@ -120,8 +118,7 @@ mapping.set<1>(1337);
std::cout << mapping.get<0>() << std::endl;
std::cout << mapping.get<1>() << std::endl;
-~~~
-{: .language-cpp}
+```
## Endianness
@@ -129,7 +126,7 @@ As you may remember this does not take endianness into account as I defined as a
_BinaryMapping_ template class which worked, but led to problems as soon as I mixed calls to _get_ and _set_. The resulting problems could of course have been fixed but this would probably
have conflicted with In-place modifications of the buffer. Because of that I chose to implement endianness support in a separate set of templates.
-~~~
+```cpp
struct BigEndianSorter {
template
static void write(uint8_t*, const Key&);
@@ -137,25 +134,23 @@ struct BigEndianSorter {
template
static Key read(uint8_t* buffer);
};
-~~~
-{: .language-cpp}
+```
To be able to work with different byte orderings I abstracted the basic operations down to _read_ and _write_ template methods contained in a _struct_ so I would be able to provide separate
implementations of these methods for each type of endianness. The following template specialization of the _write_ method which does an In-place reordering of a _uint64\_t_ should be enough
to understand the basic principle:
-~~~
+```cpp
template <>
void BigEndianSorter::write(uint8_t* buffer, const uint64_t& number) {
*reinterpret_cast(buffer) = htobe64(number);
}
-~~~
-{: .language-cpp}
+```
As soon as I had the basic endianness conversion methods implemented in a manner which could be used to specialize other template classes I was able to build a generic implementation of a
serializer which respects the structure defined by a given _std::tuple_ instantiation:
-~~~
+```cpp
template
struct Serializer {
template
@@ -205,8 +200,7 @@ struct Serializer {
);
}
};
-~~~
-{: .language-cpp}
+```
It should be evident that the way both the _serialize_ and _deserialize_ template methods are implemented is very similar to the _TupleReader_ implementation. In fact the only difference
is that no actual _std::tuple_ instantiation instance is touched and instead of setting pointers to the buffer we are only reordering the bytes of each section of the buffer corresponding to
@@ -216,7 +210,7 @@ a tuple element. This results in a complete In-place conversion between differen
At last I am now able to do everything I planned in the beginning in a very compact way using the _Serializer_, _TupleReader_ and _BinaryMapping_ templates. In practice this now looks like this:
-~~~
+```cpp
typedef std::tuple TestRecord;
uint8_t* buffer = reinterpret_cast(
@@ -245,8 +239,7 @@ std::cout << testMapping.get<1>() << std::endl;
std::free(buffer);
std::free(testBuffer);
-~~~
-{: .language-cpp}
+```
The above coding makes use of all features provided by the described templates by first setting two values using _BinaryMapping_ specialized on the _TestRecord_ tuple, serializing them using
_Serializer_ specialized on the _BigEndianSorter_, deserializing the buffer back to the host byte ordering and reading the values using another _BinaryMapping_.
diff --git a/source/00_content/articles/2013-12-21_musikalischer_jahresruekblick_2013.md b/source/00_content/articles/2013-12-21_musikalischer_jahresruekblick_2013.md
index 59f8afe..24a7286 100644
--- a/source/00_content/articles/2013-12-21_musikalischer_jahresruekblick_2013.md
+++ b/source/00_content/articles/2013-12-21_musikalischer_jahresruekblick_2013.md
@@ -12,7 +12,7 @@ auch unter diesem Namen als Album veröffentlicht wurde. Somit war für mich ab
lassen konnte. Und ich wurde nicht enttäuscht, das drei Stunden andauernde Konzert war fantastisch und bewegt sich für mich außerhalb jeder Skala, die man errichten könnte. Im Folgenden werde
ich deshalb einfach einen Ausschnitt des, auch auf DVD aufgenommenen, Konzertes für sich sprechen lassen:
-[{: .full}](https://www.youtube.com/watch?v=rxd6sxLxdys)
+[{.full}](https://www.youtube.com/watch?v=rxd6sxLxdys)
Neben Epica-eigenen Liedern, wie dem obigen Titel _Unleashed_ des 2009 erschienenen Albums _Design Your Universe_, spielte das Ensemble auch Cover von klassischen Stücken wie _Stabat Mater Dolorosa_ im Duett mit der aktuellen
Nightwish-Sängerin Floor Jansen, den _Imperial March_ des Starwars-Soundtracks sowie ein Medley der orchestralen Fassungen einiger Epica-Lieder. Das Orchester und der Chor waren also optimal
@@ -34,7 +34,7 @@ nachvollziehen. Werbung war nicht übermäßig und wenn dann hauptsächlich auf
Open-Air Veranstaltung so gut erlebt habe, Kritik üben.
Die diesjährige Band-Aufstellung des Festivals war aus meiner Sicht sehr gut, besonders zugesagt haben mir in zufälliger Reihenfolge Nightwish, Powerwolf, Sabaton, Trivium, das Lingua Mortis Orchestra und Alestorm. Als Ausschnitt hier Nightwish's _Ghost Love Score_:
-[{: .full}](https://www.youtube.com/watch?v=JYjIlHWBAVo)
+[{.full}](https://www.youtube.com/watch?v=JYjIlHWBAVo)
Neben Metal-Konzerten besuche ich auch gerne Konzerte der in meiner Gegend angesiedelten sinfonischen Blasorchester. Besonders hervorheben möchte ich dieses Jahr das in Kooperation mit einer eigens gegründeten Rock-Band durchgeführte Konzert der [Stadtmusik Stockach](http://www.musikverein-stockach.de/). Bei diesem im Oktober stattgefundenen mit [_Symphonic meets Rock_](http://www.wochenblatt.net/heute/nachrichten/article/wenn-die-grenzen-fallen.html) betitelten Konzert spielte die Stadtmusik meines Heimatortes u.a. das _Concerto for Group and Orchestra_ von Jon Lord.
diff --git a/source/00_content/articles/2014-01-05_disabling_methods_in_implicitly_instantiated_class_template_specializations_in_cpp.md b/source/00_content/articles/2014-01-05_disabling_methods_in_implicitly_instantiated_class_template_specializations_in_cpp.md
index 98740c9..61983f3 100644
--- a/source/00_content/articles/2014-01-05_disabling_methods_in_implicitly_instantiated_class_template_specializations_in_cpp.md
+++ b/source/00_content/articles/2014-01-05_disabling_methods_in_implicitly_instantiated_class_template_specializations_in_cpp.md
@@ -5,7 +5,7 @@ During my current undertaking of developing a [template based library](https://g
The specific scenario I am talking about is disabling the _serialize_ and _deserialize_ template methods in all specializations of the
_[Tuple](https://github.com/KnairdA/BinaryMapping/blob/master/src/tuple/tuple.h)_ class template whose _Endianess_ argument is not of the type _UndefinedEndian_. My first working implementation of this requirement looks as follows:
-~~~
+```cpp
template <
typename CustomOrder,
typename Helper = Endianess
@@ -16,8 +16,7 @@ inline typename std::enable_if<
>::type serialize() {
Serializer>::serialize(this->tuple_);
}
-~~~
-{: .language-cpp}
+```
As we can see I am relying on the standard library's `std::enable_if` template to enable the method only if the _Helper_ template argument equals the type _UndefinedEndian_. One may wonder why I am supplying the `std::enable_if` template with the argument _Helper_ instead of directly specifying the class template argument _Endianess_. This was needed because of the following paragraph of the ISO C++ standard:
@@ -30,7 +29,7 @@ I defined a additional _Helper_ argument which defaults to the class template's
The code supplied above works as expected but has at least two flaws: There is an additonal template argument whose sole purpose is to work around the C++ standard to make _[SFINAE](https://en.wikipedia.org/wiki/Substitution_failure_is_not_an_error)_ possible and the return type of the method is obfuscated by the use of the `std::enable_if` template.
Luckily it is not the only way of achieving our goal:
-~~~
+```cpp
template <
typename CustomOrder,
typename = typename std::enable_if<
@@ -41,8 +40,7 @@ template <
inline void serialize() {
Serializer>::serialize(this->tuple_);
}
-~~~
-{: .language-cpp}
+```
In this second example implementation we are moving the `std::enable_if` template from the return type into a unnamed default template argument of the method. This unnamed default
template argument which was not possible prior to the C++11 standard reduces the purpose of the `std::enable_if` template to selectively disabling method specializations. Additionally
@@ -50,7 +48,7 @@ the return type can be straight forwardly declared and the _Helper_ template arg
But during my research concerning this problem I came up with one additional way of achieving our goal which one could argue is even better than the second example:
-~~~
+```cpp
template
inline void serialize() {
static_assert(
@@ -60,8 +58,7 @@ inline void serialize() {
Serializer>::serialize(this->tuple_);
}
-~~~
-{: .language-cpp}
+```
This implementation of the _serialize_ method renounces any additonal template arguments and instead uses a declaration called `static_assert` which makes any specializations where
the statement `std::is_same::value` resolves to false ill-formed. Additionally it also returns a helpful message to the compiler log during such a situation.
diff --git a/source/00_content/articles/2014-07-11_mapping_arrays_using_tuples_in_cpp11.md b/source/00_content/articles/2014-07-11_mapping_arrays_using_tuples_in_cpp11.md
index 6a98630..19bc030 100644
--- a/source/00_content/articles/2014-07-11_mapping_arrays_using_tuples_in_cpp11.md
+++ b/source/00_content/articles/2014-07-11_mapping_arrays_using_tuples_in_cpp11.md
@@ -2,11 +2,11 @@
During my proof-of-concept implementation of external functions enabling [XSLT based static site generation](https://github.com/KnairdA/InputXSLT) I came upon the problem of calling a template method specialized on the Nth type of a `std::tuple` specialization using the Nth element of a array-like type instance as input. This was needed to implement a generic template-based interface for implementing [Apache Xalan](http://xalan.apache.org/xalan-c/index.html) external functions. This article aims to explain the particular approach taken to solve this problem.
-While it is possible to unpack a `std::tuple` instance into individual predefined objects using `std::tie` the standard library offers no such helper template for unpacking an array into individual objects and calling appropriate casting methods defined by a `std::tuple` mapping type. Sadly exactly this functionality is needed so that we are able to call a `constructDocument` member method of a class derived from the [`FunctionBase`](https://github.com/KnairdA/InputXSLT/blob/master/src/function/base.h) external function interface template class using static polymorphism provided through the [curiously recurring template pattern](https://en.wikipedia.org/wiki/Curiously_Recurring_Template_Pattern). This interface template accepts the desired external function arguments as variadic template types and aims to provide the required validation and conversion boilerplate implementation. While we could recursively generate a `std::tuple` specialization instance from an array-like type using a approach simmilar to the one detailed in my article on [mapping binary structures as tuples using template metaprogramming](/article/mapping_binary_structures_as_tuples_using_template_metaprogramming) this wouldn't solve the problem of passing on the resulting values as individual objects. This is why I had to take the new approach of directly calling a template method on individual array elements using a `std::tuple` specialization as a kind of blueprint and passing the result values of this method to the `constructDocument` method as separate arguments.
+While it is possible to unpack a `std::tuple` instance into individual predefined objects using `std::tie` the standard library offers no such helper template for unpacking an array into individual objects and calling appropriate casting methods defined by a `std::tuple` mapping type. Sadly exactly this functionality is needed so that we are able to call a `constructDocument` member method of a class derived from the [FunctionBase](https://github.com/KnairdA/InputXSLT/blob/master/src/function/base.h) external function interface template class using static polymorphism provided through the [curiously recurring template pattern](https://en.wikipedia.org/wiki/Curiously_Recurring_Template_Pattern). This interface template accepts the desired external function arguments as variadic template types and aims to provide the required validation and conversion boilerplate implementation. While we could recursively generate a `std::tuple` specialization instance from an array-like type using a approach simmilar to the one detailed in my article on [mapping binary structures as tuples using template metaprogramming](/article/mapping_binary_structures_as_tuples_using_template_metaprogramming) this wouldn't solve the problem of passing on the resulting values as individual objects. This is why I had to take the new approach of directly calling a template method on individual array elements using a `std::tuple` specialization as a kind of blueprint and passing the result values of this method to the `constructDocument` method as separate arguments.
Extracting array elements obviously requires some way of defining the appropriate indexes and mapping the elements using a tuple blueprint additionally requires this way to be statically resolvable as one can not pass a dynam