
diff options
| author | Adrian Kummerlaender | 2017-01-17 20:44:31 +0100 |
|---|---|---|
| committer | Adrian Kummerlaender | 2017-01-17 20:44:31 +0100 |
| commit | 9bb990c9a663edc43aebb87ed84b00e6d90685c0 (patch) | |
| tree | fcb40f5c4f94f7e1b89d3495a20d82e4cbd6db90 | |
| parent | b84e7973d91e066aa3c0e9e5660e30401916fd5f (diff) | |
| download | blog_content-9bb990c9a663edc43aebb87ed84b00e6d90685c0.tar blog_content-9bb990c9a663edc43aebb87ed84b00e6d90685c0.tar.gz blog_content-9bb990c9a663edc43aebb87ed84b00e6d90685c0.tar.bz2 blog_content-9bb990c9a663edc43aebb87ed84b00e6d90685c0.tar.lz blog_content-9bb990c9a663edc43aebb87ed84b00e6d90685c0.tar.xz blog_content-9bb990c9a663edc43aebb87ed84b00e6d90685c0.tar.zst blog_content-9bb990c9a663edc43aebb87ed84b00e6d90685c0.zip | |
Update markdown syntax to use pandoc's peculiarities
39 files changed, 328 insertions, 382 deletions
diff --git a/articles/2010-02-06_debian_auf_dem_sheevaplug.md b/articles/2010-02-06_debian_auf_dem_sheevaplug.md index c7bc555..fb82abb 100644 --- a/articles/2010-02-06_debian_auf_dem_sheevaplug.md +++ b/articles/2010-02-06_debian_auf_dem_sheevaplug.md @@ -4,54 +4,48 @@ Auf dem herkömmlichen [Weg](http://www.cyrius.com/debian/kirkwood/sheevaplug/) Als erstes laden wir uns den normalen SheevaInstaller herunter mit dem man Ubuntu 9.04 auf dem Sheeva installieren kann ([klick](http://www.plugcomputer.org/index.php/us/resources/downloads?func=select&id=5)). Nach dem wir den Tarball heruntergeladen haben sollte man ihn entpacken. Als nächstes laden wir ein Debian Lenny / Squeeze Prebuild von [hier](http://www.mediafire.com/sheeva-with-debian) herunter. Nun ersetzen wir die „rootfs.tar.gz“ mit der neuen Debian „rootfs.tar.gz“. Bevor wir jedoch mit der Installation beginnen müssen wir die neue „rootfs.tar.gz“ mit „tar“ entpacken. Dazu führen wir auf der Konsole -~~~ +```sh mkdir rootfs cd rootfs tar xfvz rootfs.tar.gz -~~~ -{: .language-sh} +``` aus. In dem Ordner führen wir nun ein -~~~ +```sh mknod -m 660 dev/ttyS0 c 4 64 -~~~ -{: .language-sh} +``` aus. Mit diesem Befehl wird die fehlende serielle Konsole erstellt. Jetzt verpacken wir das Archiv wieder mit -~~~ +```sh tar cfvz ../rootfs.tar.gz * -~~~ -{: .language-sh} +``` Den gesamten Inhalt des Ordners /install im SheevaInstaller-Verzeichniss müssen wir jetzt auf einen mit FAT formatierten USB-Stick kopieren. Diesen stecken wir schon einmal in den USB-Port des Sheevas. Als nächstes verbinden wir den SheevaPlug mit einem Mini-USB Kabel mit unserem Computer und führen das Script „runme.php“ aus. Wenn alles klappt wird nun ein neuer Boot-Loader und das rootfs auf den Plug kopiert. Dannach ist unser Debian einsatzbereit. Sollte der Plug den USB-Stick nicht erkennen und somit auch das rootfs nicht kopieren können hilft es einen anderen USB-Stick zu verwenden. Beispielsweise wurde mein SanDisk U3 Stick trotz gelöschtem U3 nicht erkannt. Mit einem anderen Stick funktionierte es jedoch tadelos. Auch sollte der Stick partitioniert sein. Der Bootloader des SheevaPlugs kann nicht gut mit direkt auf dem Stick enthalten Dateisystemen umgehen. Wenn die MiniUSB Verbindung beim Ausführen des runme-Scripts nicht funktionieren sollte hilft oft ein -~~~ +```sh rmmod ftdi_sio -~~~ -{: .language-sh} +``` und -~~~ +```sh modprobe ftdi_sio vendor=0x9e88 product=0x9e8f -~~~ -{: .language-sh} +``` (beides als root). Ebenfalls sollte kein zweites Serielles-Gerät am Computer angeschlossen sein. Bei neueren Plugs kann man bei Problemen bei der Installation die Datei „uboot/openocd/config/interface/sheevaplug.cfg“ im SheevaInstaller-Ordner nach -~~~ +```sh interface ft2232 ft2232_layout sheevaplug ft2232_vid_pid 0×0403 0×6010 #ft2232_vid_pid 0x9e88 0x9e8f #ft2232_device_desc “SheevaPlug JTAGKey FT2232D B” jtag_khz 2000 -~~~ -{: .language-sh} +``` umändern. Wenn Debian jetzt auf dem SheevaPlug läuft und man sich über SSH einloggen konnte (pwd: nosoup4u), sollte man als erstes ein Update machen. diff --git a/articles/2010-02-24_traffic_ueberwachung_mit_vnstat.md b/articles/2010-02-24_traffic_ueberwachung_mit_vnstat.md index 309852c..9178cab 100644 --- a/articles/2010-02-24_traffic_ueberwachung_mit_vnstat.md +++ b/articles/2010-02-24_traffic_ueberwachung_mit_vnstat.md @@ -3,7 +3,7 @@ Heute möchte ich euch ein kleines und praktisches Programm zum Überwachen des Netzwerkverkehrs vorstellen: [vnstat](http://humdi.net/vnstat/). vnStat ist ein konsolenbasierter Netzwerkverkehrmonitor der Logs mit der Menge des Datenverkehrs auf beliebigen Netzwerkschnittstellen speichert. Aus diesen Logs generiert vnStat dann diverse Statistiken. -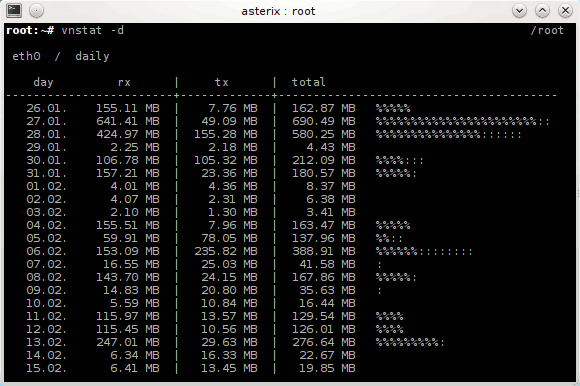{: .full} +{.full} Installieren kann man vnstat unter Debian bequem aus den Paketquellen mit `apt-get install vnstat` oder unter ArchLinux mit `pacman -S vnstat`. Gestartet wird vnStat mit `vnstat`. Sobald der Daemon läuft schreibt vnstat den aktuellen Netzwerkverkehr in eine Datenbank. Durch Anhängen von Argumenten kann man jetzt schöne Statistiken auf der Konsole ausgeben, z.B. eine Statistik über die letzten Tage mit `vnstat -d` (siehe Bild) oder über die letzten Wochen mit `vnstat -w`. Eine Übersicht über alle möglichen Argumente bekommt man wie Üblich über `vnstat –help`. Eine sehr Interessante Funktion wie ich finde ist die Möglichkeit zur live-Anzeige des Verkehrs mit `vnstat -h`. diff --git a/articles/2010-07-12_ocr_und_automatische_uebersetzung_mit_dem_n900.md b/articles/2010-07-12_ocr_und_automatische_uebersetzung_mit_dem_n900.md index 150f747..7ccc7ec 100644 --- a/articles/2010-07-12_ocr_und_automatische_uebersetzung_mit_dem_n900.md +++ b/articles/2010-07-12_ocr_und_automatische_uebersetzung_mit_dem_n900.md @@ -2,15 +2,15 @@ Heute bin ich auf einem Streifzug durch das Maemo5 testing-Repository auf ein sehr praktisches Programm gestoßen: PhotoTranslator. Mit ihm lässt sich der Text aus Bildern extrahieren und mittels Google-Translate übersetzen. -{: .full width="600px"} +{.full width="600px"} Das ist z.B. praktisch um fremdsprachige Speisekarten o.ä. in die eigene Sprache zu übersetzen. Nachdem man ein Bild ausgewählt oder direkt aus dem Programm heraus eines erstellt hat (funktioniert in der aktuellen Alpha-Version von PhotoTranslator noch nicht richtig) muss man als erstes den gewünschten Textteil mittels eines Rahmens, wie man ihn auch zum Zuschneiden von Fotos im Bildbetrachter des N900 verwendet auswählen – zur Zeit geht das jedoch leider nur mit einzelnen Zeilen und nicht mit ganzen Textblöcken. -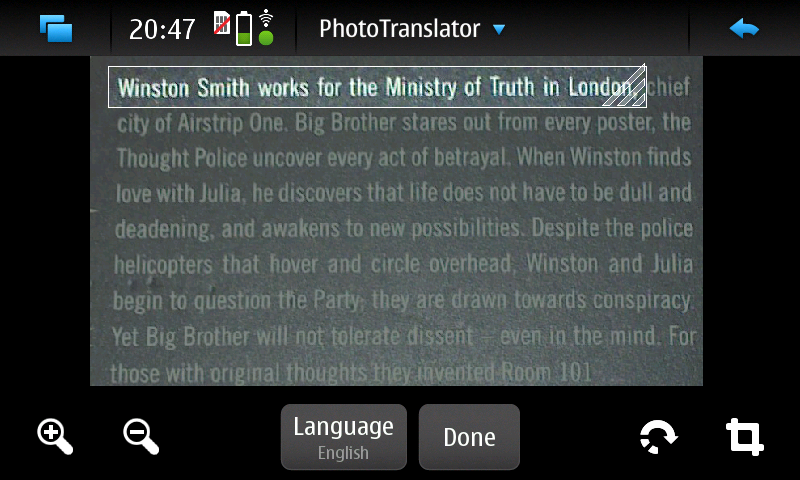{: .full width="600px"} +{.full width="600px"} Danach muss man nurnoch die Ausgangs und Zielsprache wählen, kurz warten und schon bekommt man den eingescannten Ausgangstext und die Übersetzung präsentiert. Das funktioniert auch schon in dieser frühen Alpha-Version sehr gut. -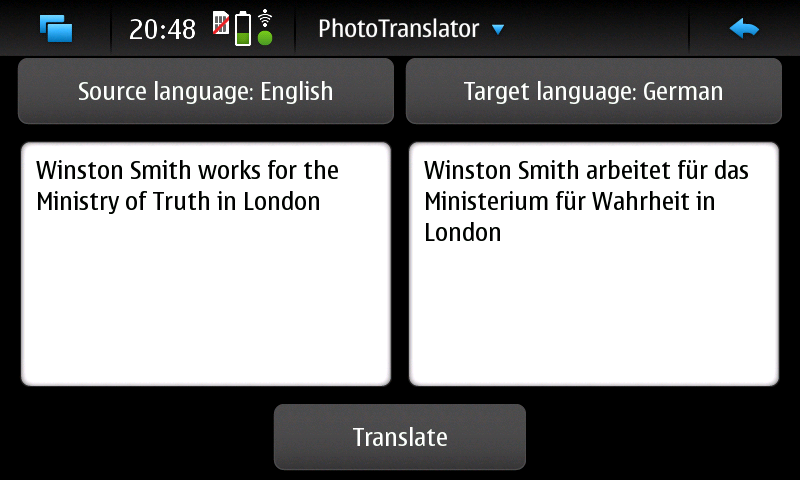{: .full width="600px"} +{.full width="600px"} PhotoTranslator lässt sich aber nicht nur zum Übersetzen von Bildern, sondern auch als einfache Oberfläche für Google-Translate mit Texteingabe über die Tastatur verwenden. Weitere Informationen und ein Demo-Video findet ihr unter [cybercomchannel.com](http://www.cybercomchannel.com/?p=63). Installieren lässt sich PhotoTranslator bei aktivierten extras-testing Repositories bequem aus der Paketverwaltung des N900 heraus. diff --git a/articles/2011-03-31_sheevaplug_ueberwachung.md b/articles/2011-03-31_sheevaplug_ueberwachung.md index 89ac393..311f34c 100644 --- a/articles/2011-03-31_sheevaplug_ueberwachung.md +++ b/articles/2011-03-31_sheevaplug_ueberwachung.md @@ -4,15 +4,14 @@ Um den Überblick über die Auslastung und den Traffic meines SheevaPlugs zu beh Den Systemmonitor Conky lasse ich mit dem Befehl `ssh -X -vv -Y -p 22 adrian@asterix "conky -c /home/adrian/.conkyrc"` über X-forwarding in meiner XFCE-Session anzeigen. Das klappt einwandfrei und ergibt zusammen mit dieser [Conky-Konfiguration](http://adrianktools.redirectme.net/files/.conkyrc) und einer lokalen Conky-Instanz folgendes Bild: -{: .full} +{.full} Zusätzlich loggt der SheevaPlug regelmäßig die aktuellen Systemdaten wie CPU-Auslastung, Netzwerkverkehr und belegten Arbeitsspeicher und generiert sie zu Graphen die mir dann jede Nacht per eMail zugesand werden. Zum Loggen der Daten verwende ich dstat das mit folgendem, von einem Cron-Job gestarteten Befehl aufgerufen wird: -~~~ +```sh dstat -tcmn 2 1 | tail -1 >> /var/log/systat.log -~~~ -{: .language-sh} +``` Die Argumente -tcmn geben hierbei die zu loggenden Systemdaten und deren Reihenfolge an – heraus kommen Zeilen wie diese: @@ -20,7 +19,7 @@ Die Argumente -tcmn geben hierbei die zu loggenden Systemdaten und deren Reihenf Um 0 Uhr wird dann die Log-Datei von einem Cron-Job mit diesem Script wegkopiert, Graphen werden von gnuplot generiert und dann mit einem kleinen Python-Programm versendet. -~~~ +```sh #!/bin/sh mv /var/log/systat.log /root/sys_graph/stat.dat cd /root/sys_graph/ @@ -28,12 +27,11 @@ cd /root/sys_graph/ ./generate_memory.plot ./generate_network.plot ./send_report.py -~~~ -{: .language-sh} +``` Hier das gnuplot-Script zur Erzeugung des CPU-Graphen als Beispiel: -~~~ +```sh #!/usr/bin/gnuplot set terminal png set output "cpu.png" @@ -46,12 +44,11 @@ set format x "%H:%M" plot "stat.dat" using 1:4 title "system" with lines, \ "stat.dat" using 1:3 title "user" with lines, \ "stat.dat" using 1:5 title "idle" with lines -~~~ -{: .language-sh} +``` … und hier noch das Python-Programm zum Versenden per Mail: -~~~ +```python #!/usr/bin/python2 import smtplib from time import * @@ -82,12 +79,11 @@ s.login('mail@mail.mail', '#####') s.sendmail('mail@mail.mail', 'mail@mail.mail', msg.as_string()) s.quit() -~~~ -{: .language-python} +``` Als Endergebniss erhalte ich dann täglich solche Grafiken per Mail: -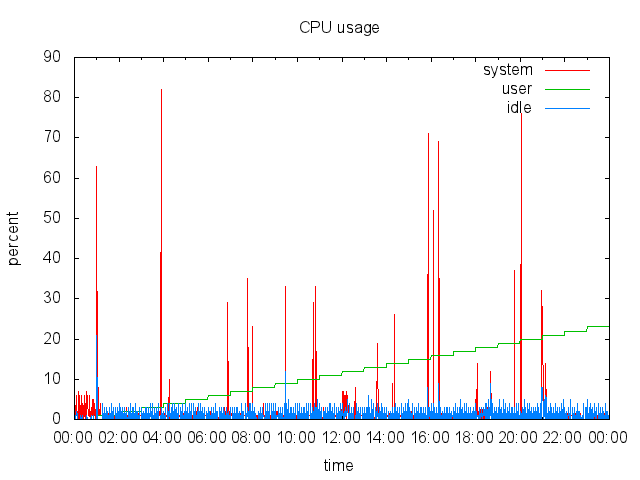{: .full .clear} +{.full .clear} Ich finde es immer wieder erstaunlich mit wie wenigen Zeilen Quelltext man interessante Sachen unter Linux erzeugen kann – oder besser wie viel Programme wie gnuplot mit nur wenigen Anweisungen erzeugen können. So hat das komplette Schreiben dieser Scripts mit Recherche nur etwa 1,5 Stunden gedauert – inklusive Testen. Alle verwendeten Programme sind in den ArchLinux Paketquellen vorhanden – auch in denen von PlugBox-Linux, einer Portierung von ArchLinux auf ARM-Plattformen die ich nur immer wieder empfehlen kann – besonders nach den jetzt oft erscheinenden Paket-Updates. Aber dazu auch dieser Artikel: [Plugbox Linux – Ein ArchLinux Port für den SheevaPlug](/article/plugbox_linux_ein_archlinux_port_fuer_den_sheevaplug/). diff --git a/articles/2011-06-14_darstellen_von_gps_daten_mit_gnuplot.md b/articles/2011-06-14_darstellen_von_gps_daten_mit_gnuplot.md index cc97add..28c95de 100644 --- a/articles/2011-06-14_darstellen_von_gps_daten_mit_gnuplot.md +++ b/articles/2011-06-14_darstellen_von_gps_daten_mit_gnuplot.md @@ -4,19 +4,18 @@ Bei meiner letzten Wanderung in den Schweizer Alpen habe ich spaßeshalber das N Die Daten der Messpunkte sind im XML als `trkpt`-Tags gespeichert. Enthalten sind jeweils der Längen- und Breitengrad, die Uhrzeit, der Modus (3d / 2d), die Höhe über Null und die Anzahl der zur Positionsbestimmung genutzten Satelliten. Aussehen tut das ganze dann z.B. so: -~~~ +```xml <trkpt lat="47.320591" lon="9.329439"> <time>2011-06-12T07:57:39Z</time> <fix>3d</fix> <ele>870</ele> <sat>6</sat> </trkpt> -~~~ -{: .language-xml} +``` Diese Daten lassen sich nun sehr einfach Verarbeiten – ich habe das Python `xml.dom.minidom` Modul verwendet. Um die Positionen einfacher verwenden zu können, werden sie mit dieser Funktion in Listenform gebracht: -~~~ +```python def getPositions(xml): doc = minidom.parse(xml) node = doc.documentElement @@ -29,12 +28,11 @@ def getPositions(xml): pos["ele"] = int(TrkPt.getElementsByTagName("ele")[0].childNodes[0].nodeValue) positions.append(pos) return positions -~~~ -{: .language-python} +``` Aus dieser Liste kann ich jetzt schon einige Kennzahlen ziehen: -~~~ +```python def printStats(gpxPositions): highEle = gpxPositions[0]["ele"] lowEle = gpxPositions[0]["ele"] @@ -48,8 +46,7 @@ def printStats(gpxPositions): print "Lowest elevation: " + str(lowEle) print "Highest elevation: " + str(highEle) print "Height difference: " + str(eleDiv) -~~~ -{: .language-python} +``` Die Kennzahlen für meine Testdaten wären: @@ -61,21 +58,20 @@ Die Kennzahlen für meine Testdaten wären: Da die Daten ja, wie schon im Titel angekündigt, mit gnuplot dargestellt werden sollen werden sie mit dieser Funktion in für gnuplot lesbares CSV gebracht: -~~~ +```python def printCsv(gpxPositions): separator = ';' for pos in gpxPositions: print pos["lat"] + separator + pos["lon"] + separator + str(pos["ele"]) -~~~ -{: .language-python} +``` ## Plotten mit gnuplot -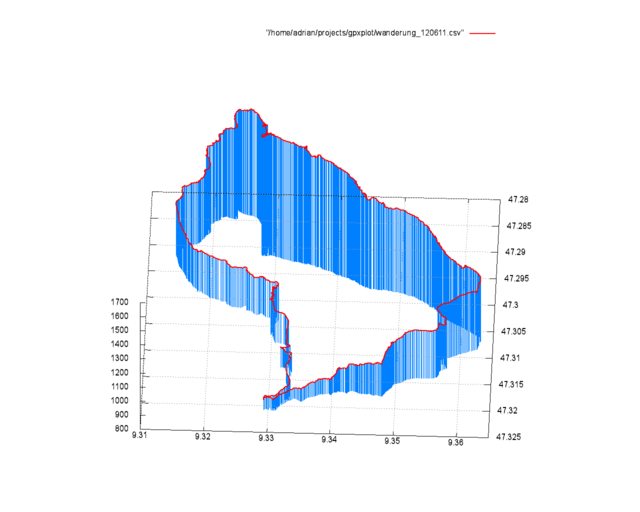{: .full .clear} +{.full .clear} Eine solche, dreidimensionale Ausgabe der GPS Daten zu erzeugen ist mit der `splot`-Funktion sehr einfach. -~~~ +```sh #!/usr/bin/gnuplot set terminal png size 1280,1024 set output "output.png" @@ -90,16 +86,14 @@ set datafile separator ';' splot "/home/adrian/projects/gpxplot/wanderung_120611.csv" with impulses lt 3 lw 1 splot "/home/adrian/projects/gpxplot/wanderung_120611.csv" with lines lw 2 unset multiplot -~~~ -{: .language-sh} +``` Mit `set terminal png size 1280,1024` und `set output "output.png"` werden zuerst das Ausgabemedium, die Größe und der Dateiname der Ausgabe definiert. Dannach aktiviert `set multiplot` den gnuplot-Modus, bei dem mehrere Plots in einer Ausgabe angezeigt werden können. Dieses Verhalten brauchen wir hier, um sowohl die Strecke selbst als rote Line, als auch die zur Verdeutlichung verwendeten blauen Linien gleichzeitig anzuzeigen. Mit `set [y,x,z]range` werden die Außengrenzen des zu plottenden Bereichs gesetzt. Dies ließe sich natürlich auch über ein Script automatisch erledigen. Als Nächstes wird mit `set view 28,272,1,1` die Blickrichtung und Skalierung definiert. `set ticslevel 0` sorgt dafür, dass die Z-Achse direkt auf der Grundebene beginnt. Um ein Gitter auf der Grundfläche anzuzeigen, gibt es `set grid`. Als letztes werden jetzt die zwei Plots mit `splot` gezeichnet. Die Angaben hinter `with` steuern hierbei das Aussehen der Linien. -Falls jemand den Artikel mit meinen Daten nachvollziehen möchte - das GPX-File kann hier heruntergeladen werden: - [2011-06-12.gpx](https://static.kummerlaender.eu/media/2011-06-12.gpx) +Falls jemand den Artikel mit meinen Daten nachvollziehen möchte - das GPX-File kann hier heruntergeladen werden: [2011-06-12.gpx](https://static.kummerlaender.eu/media/2011-06-12.gpx) Zum Schluss hier noch ein Blick vom Weg auf den Kronberg Richtung Jakobsbad im Appenzell: -{: .full} +{.full} diff --git a/articles/2011-09-03_die_sache_mit_dem_netzteil.md b/articles/2011-09-03_die_sache_mit_dem_netzteil.md index c96d7d5..4da8fdb 100644 --- a/articles/2011-09-03_die_sache_mit_dem_netzteil.md +++ b/articles/2011-09-03_die_sache_mit_dem_netzteil.md @@ -2,6 +2,6 @@ Diese Woche hat meinen SheevaPlug das selbe Schicksal getroffen wie viele andere auch – nach dem Urlaub war das Netzteil kaputt. Mit einem externen von [Conrad](http://www.conrad.de/ce/de/product/510820/Dehner-SYS1308-Netzt-fests-5V15W%22%22) geht er jetzt aber wieder einwandfrei. -{: .full} +{.full} Als sehr nützlich, um in der Zeit bis der Plug repariert war wenigstens eine _Netzteil-Kaputt_-Meldung auf der Webseite anzeigen zu können, erwies sich [Staticloud](http://staticloud.com) – ein netter Webservice um statische Webseiten per drag ‘n drop kostenlos in der Amazon-Cloud hosten zu können. Um die Inhalte zugänglich zu halten (Backup habe ich natürlich schon – aber bis jetzt nur als MySQL-Dump, ab jetzt wohl auch das ganze als HTML ) half mir Google – der gesammte Blog hängt praktischerweise dort im Cache. diff --git a/articles/2011-10-01_lighttpd_konfiguration_fuer_symphony.md b/articles/2011-10-01_lighttpd_konfiguration_fuer_symphony.md index fade6af..90fa82e 100644 --- a/articles/2011-10-01_lighttpd_konfiguration_fuer_symphony.md +++ b/articles/2011-10-01_lighttpd_konfiguration_fuer_symphony.md @@ -4,14 +4,16 @@ Da ich die Neuauflage dieser Seite nicht mehr auf Wordpress, sondern auf dem [Sy Von den im Netz verfügbaren [Beispielen](http://blog.ryara.net/2009/12/05/lighttpd-rewrite-rules-for-symphony-cms/) hat jedoch keines ohne Einschränkungen funktioniert. Aus diesem Grund habe ich auf Basis der oben verlinkten Konfiguration ein funktionierendes Regelwerk geschrieben: - url.rewrite-once += ( - "^/favicon.ico$" => "$0", - "^/robots.txt$" => "$0", - "^/symphony/(assets|content|lib|template)/.*$" => "$0", - "^/workspace/([^?]*)" => "$0", - "^/symphony(\/(.*\/?))?(.*)\?(.*)$" => "/index.php?symphony-page=$1&mode=administration&$4&$5", - "^/symphony(\/(.*\/?))?$" => "/index.php?symphony-page=$1&mode=administration", - "^/([^?]*/?)(\?(.*))?$" => "/index.php?symphony-page=$1&$3" - ) +``` +url.rewrite-once += ( + "^/favicon.ico$" => "$0", + "^/robots.txt$" => "$0", + "^/symphony/(assets|content|lib|template)/.*$" => "$0", + "^/workspace/([^?]*)" => "$0", + "^/symphony(\/(.*\/?))?(.*)\?(.*)$" => "/index.php?symphony-page=$1&mode=administration&$4&$5", + "^/symphony(\/(.*\/?))?$" => "/index.php?symphony-page=$1&mode=administration", + "^/([^?]*/?)(\?(.*))?$" => "/index.php?symphony-page=$1&$3" +) +``` Dieses läuft mit der aktuellsten Symphony Version einwandfrei. Zu finden ist die Konfiguration übrigens mit den restlichen Quellen meines neuen Webseiten-Setups auf [Github](https://github.com/KnairdA/blog.kummerlaender.eu). diff --git a/articles/2011-10-02_tarsnap_backups_fuer_paranoide.md b/articles/2011-10-02_tarsnap_backups_fuer_paranoide.md index 7aedf41..d3dca15 100644 --- a/articles/2011-10-02_tarsnap_backups_fuer_paranoide.md +++ b/articles/2011-10-02_tarsnap_backups_fuer_paranoide.md @@ -4,23 +4,29 @@ Für meine Backups nutze ich jetzt seit einiger Zeit den Online-Service [Tarsnap Das ganze ist so aufgebaut, dass immer nur veränderte und neue Dateien übertragen werden müssen. Alle Daten werden schon vom Client verschlüsselt, sodass keine unverschlüsselten Daten übers Netzwerk fließen und weder die Entwickler von Tarsnap noch Amazon den Inhalt der Daten auslesen können. -Der Service ist nicht kostenlos, aber sehr günstig - der Preis pro Byte Speicher / Datenverkehr beträgt 300 Picodollar, ein Gigabyte kostet also pro Monat nur 0,30$. +Der Service ist nicht kostenlos, aber sehr günstig - der Preis pro Byte Speicher / Datenverkehr beträgt 300 Picodollar, ein Gigabyte kostet also pro Monat nur 0,30 Dollar. Der Tarsnap-Client ist im Quellcode verfügbar (aber nicht unter einer Open Source Lizenz) und lässt sich problemlos auch auf ARM Prozessoren kompilieren, sodass ich auch vom N900 und SheevaPlug aus Zugriff auf meine Backups haben kann. Die Authentifizierung mit dem Server funktioniert über einen Schlüssel, der sich nach Eingabe des Passworts mit folgendem Befehl generieren lässt: - tarsnap-keygen --keyfile [pfad-zum-schlüssel] --user [email] --machine [hostname] +```sh +tarsnap-keygen --keyfile [pfad-zum-schlüssel] --user [email] --machine [hostname] +``` Die resultierende Datei ermöglicht ohne zusätzliche Authentifizierung Zugriff auf die Backups und sollte somit sicher aufbewahrt werden und nicht in falsche Hände geraten, denn ohne sie hat man keinen Zugriff mehr auf seine Daten. Ein neues Backup lässt sich über diesen Befehl anlegen: - tarsnap -c -f [name-des-backups] [zu-sichernder-pfad] +```sh +tarsnap -c -f [name-des-backups] [zu-sichernder-pfad] +``` Jedes weitere Backup geht danach um einiges schneller weil Tarsnap nur veränderte Daten überträgt. Standardmäßig wird dieser Cache unter "/usr/local/tarsnap-cache" und der Schlüssel unter "/root/tarsnap.key" erwartet, dies lässt sich jedoch über entsprechende Parameter steuern - näheres dazu findet sich auf der [Manpage](http://www.tarsnap.com/man-tarsnap.1.html). Sollte man dann einmal in die nicht wünschenswerte Situation kommen Zugriff auf sein Backup zu benötigen, reicht dieser Befehl um die Daten wiederherzustellen: - tarsnap -x -f [name-des-backups] [wiederherzustellender-pfad] +```sh +tarsnap -x -f [name-des-backups] [wiederherzustellender-pfad] +``` Tarsnap kann ich wirklich empfehlen, es hat mich vom [Konzept](http://www.tarsnap.com/design.html) und der Umsetzung her voll überzeugt und ist auf jeden Fall eine ernst zunehmende Alternative zu anderen Backuplösungen in der _Wolke_. diff --git a/articles/2011-10-16_kurztipp_n900_retten_ohne_neu_zu_flashen.md b/articles/2011-10-16_kurztipp_n900_retten_ohne_neu_zu_flashen.md index f59b709..4084d69 100644 --- a/articles/2011-10-16_kurztipp_n900_retten_ohne_neu_zu_flashen.md +++ b/articles/2011-10-16_kurztipp_n900_retten_ohne_neu_zu_flashen.md @@ -7,9 +7,8 @@ Erst sah es so aus, als würde ich nicht darum herum kommen das Betriebsystem ne Dabei handelt es sich um ein kleines Linux welches mithilfe des normalen [Flashers](http://tablets-dev.nokia.com/maemo-dev-env-downloads.php) direkt in den RAM des N900 kopiert und dort gebootet werden kann. Vom rescueOS aus kann man dann das Root-Dateisystem problemlos einbinden und Probleme beheben. Zum Starten reicht das [initrd Image](http://n900.quitesimple.org/rescueOS/rescueOS-1.0.img) und folgender Befehl: -~~~ +```sh flasher-3.5 -k 2.6.37 -n initrd.img -l -b"rootdelay root=/dev/ram0" -~~~ -{: .language-sh} +``` Nähere Informationen zur Verwendung und den Funktionen finden sich in der rescueOS [Dokumentation](http://n900.quitesimple.org/rescueOS/documentation.txt). diff --git a/articles/2011-11-08_informationen_umformen_mit_xsl.md b/articles/2011-11-08_informationen_umformen_mit_xsl.md index 7785b83..f84f17c 100644 --- a/articles/2011-11-08_informationen_umformen_mit_xsl.md +++ b/articles/2011-11-08_informationen_umformen_mit_xsl.md @@ -8,7 +8,7 @@ Schlussendlich habe ich dann eine [XSLT](http://de.wikipedia.org/wiki/XSLT) gesc Mit XSL lassen sich XML Dateien in andere Formen bringen. Da Mediawiki mehr oder weniger valides XHTML ausgibt, kann man, nachdem das XHTML mit [Tidy](http://tidy.sourceforge.net) ein wenig aufgeräumt wurde, sehr einfach die [Terminliste](http://wiki.piratenpartei.de/BW:Kreisverband_Konstanz/Termine) extrahieren und gleichzeitig in RSS umformen: -~~~ +```xsl <xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform" xmlns:x="http://www.w3.org/1999/xhtml" @@ -57,8 +57,7 @@ Mit XSL lassen sich XML Dateien in andere Formen bringen. Da Mediawiki mehr oder <xsl:template match="text()"/> </xsl:stylesheet> -~~~ -{: .language-xsl} +``` Der Kern dieses XSL ist nicht mehr als ein Template welches auf den [XPATH](http://de.wikipedia.org/wiki/XPATH) zum Finden der Terminliste reagiert. Die For-Each-Schleife iteriert dann durch die Termine und formt diese entsprechend in RSS um. Der einzige Knackpunkt kommt daher, dass XHTML kein normales XML ist und somit seinen eigenen Namespace hat. Diesen sollte man im Element `xsl:stylesheet` korrekt angeben, sonst funktioniert nichts. Auch muss im XPATH Ausdruck dann vor jedem Element ein `x:` eingefügt werden um dem XSL Prozessor den Namespace für das jeweilige Element mitzuteilen. @@ -72,17 +71,16 @@ Zum Anpassen des Datums verwende ich - wie auch in diesem Blog - die [date-time. Mit der eben beschriebenen XSLT lässt sich jetzt in drei Schritten das fertige RSS generieren: -~~~ +```sh #!/bin/sh wget -O termine_wiki.html "http://wiki.piratenpartei.de/BW:Kreisverband_Konstanz/Termine" tidy -asxml -asxhtml -O termine_tidy.html termine_wiki.html xsltproc --output termine_kvkn.rss --novalid termine_kvkn.xsl termine_tidy.html -~~~ -{: .language-sh} +``` In PHP ist das ganze dann zusammen mit sehr einfachem Caching auch direkt auf einem Webserver einsetzbar: -~~~ +```php define('CACHE_TIME', 6); define('CACHE_FILE', 'rss.cache'); @@ -139,5 +137,4 @@ function generate_rss() return false; } } -~~~ -{: .language-php} +``` diff --git a/articles/2012-01-25_erfahrungen_mit_openslides.md b/articles/2012-01-25_erfahrungen_mit_openslides.md index 2804605..b670400 100644 --- a/articles/2012-01-25_erfahrungen_mit_openslides.md +++ b/articles/2012-01-25_erfahrungen_mit_openslides.md @@ -6,13 +6,13 @@ OpenSlides ist ein auf dem Python-Webframework [Django](https://www.djangoprojec Das UI ist dabei in den Administrationsbereich, über den sämtliche Daten eingegeben werden können, und eine Beamer-Ansicht geteilt. Beide dieser Komponenten laufen in einem gewöhnlichen Webbrowser. Das Aussehen lässt sich also einfach durch Modifikation der Templates und der CSS-Formatierungen an die eigenen Wünsche anpassen. -{: .full} +{.full} Nachdem ich anfangs alle Wahlen, bekannten Teilnehmer und Anträge in das Redaktionsystem eingespiesen hatte, ließ sich am Parteitag selbst dann mit wenigen Mausklicks eine ansprechende Präsentation des aktuellen Themas erzeugen. Wahlergebnisse waren ebenso wie die Annahme oder Ablehnung eines Antrags über entsprechende Formulare schnell eingepflegt und dargestellt. Sehr gefallen hat mir im Vorfeld auch die Möglichkeit der Generierung von Antragsbüchern als PDF. -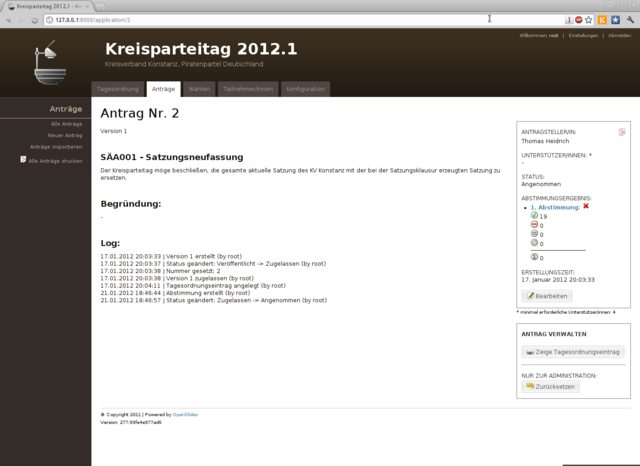{: .full} +{.full} Der Funktionsumfang von OpenSlides geht jedoch über die bloße Darstellung der TO auf einem Beamer hinaus. So kann wenn gewünscht jeder Teilnehmer über sein eigenes Endgerät auf das Webinterface zugreifen und als Deligierter an der Versammlung teilnehmen - also Abstimmen, Wählen und Anträge stellen. Theoretisch ermöglicht es diese Software also - bei entsprechender Authentifizierung - die Durchführung von dezentralen Versammlungen. Aber auch wenn dies z.B. aufgrund von zur Nachvollziehbarkeit nötiger Klarnamenspflicht nicht in Frage kommt, ergibt sich doch so für die Teilnehmer immerhin die Möglichkeit den Ablauf auf einem eigenen Gerät nachzuverfolgen. @@ -20,7 +20,7 @@ Theoretisch ermöglicht es diese Software also - bei entsprechender Authentifizi Der einzige Punkt der mich wirklich störte war die fehlende Anzeige von Wahlergebnissen der Teilnehmer die eine Wahl verloren hatten. Die jeweilige Stimmenzahl war im Frontend erst sichtbar nachdem der entsprechende Kandidat als Sieger markiert worden war. Doch auch dieses Problem ließ sich - OpenSource sei Dank - schnell über manuelles Eingreifen im Quelltext korrigieren: -~~~ +```diff --- /home/adrian/Downloads/original_views.py +++ /opt/hg.openslides.org/openslides/agenda/views.py @@ -132,14 +132,11 @@ @@ -42,8 +42,7 @@ Doch auch dieses Problem ließ sich - OpenSource sei Dank - schnell über manuel else: tmplist[1].append("-") votes.append(tmplist) -~~~ -{: .language-diff} +``` OpenSlides ist wirklich ein tolles Stück Software und ich kann nur jedem der vor der Aufgabe steht eine Versammlung zu organisieren, sei es die eines Vereins oder wie in meinem Fall die einer Partei, empfehlen sich es einmal näher anzusehen. Weitere Angaben zur Installation und Konfiguration finden sich auf der [Webpräsenz](http://openslides.org/de/index.html) und im [Quell-Archiv](http:/ |